Создание архитектуры программы или как проектировать табуретку / Хабр
Взявшись за написание небольшого, но реального и растущего проекта, мы «на собственной шкуре» убедились, насколько важно то, чтобы программа не только хорошо работала, но и была хорошо организована. Не верьте, что продуманная архитектура нужна только большим проектам (просто для больших проектов «смертельность» отсутствия архитектуры очевидна). Сложность, как правило, растет гораздо быстрее размеров программы. И если не позаботиться об этом заранее, то довольно быстро наступает момент, когда ты перестаешь ее контролировать. Правильная архитектура экономит очень много сил, времени и денег. А нередко вообще определяет то, выживет ваш проект или нет. И даже если речь идет всего лишь о «построении табуретки» все равно вначале очень полезно ее спроектировать.
К моему удивлению оказалось, что на вроде бы актуальный вопрос: «Как построить хорошую/красивую архитектуру ПО?» — не так легко найти ответ. Не смотря на то, что есть много книг и статей, посвященных и шаблонам проектирования и принципам проектирования, например, принципам SOLID (кратко описаны тут, подробно и с примерами можно посмотреть тут, тут и тут) и тому, как правильно оформлять код, все равно оставалось чувство, что чего-то важного не хватает.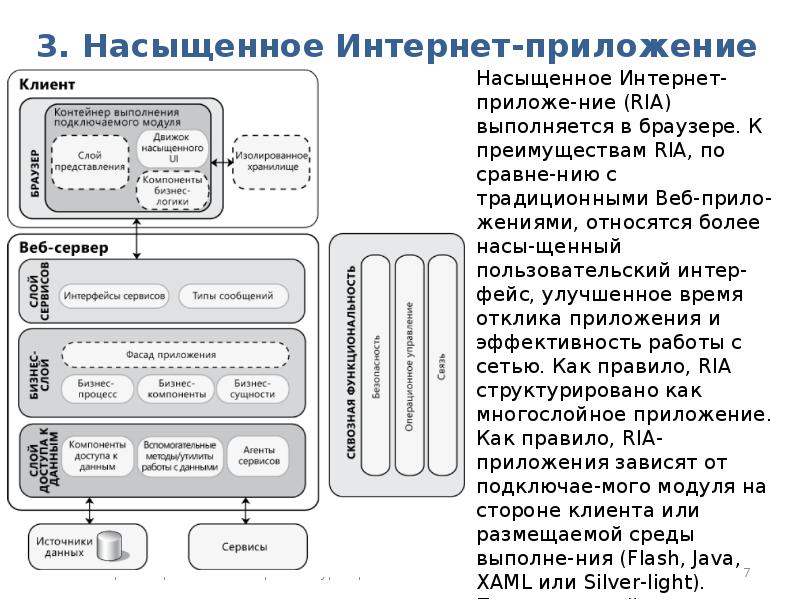
Хотелось разобраться, что вообще в себя включает процесс создания архитектуры программы, какие задачи при этом решаются, какие критерии используются (чтобы правила и принципы перестали быть всего лишь догмами, а стали бы понятны их логика и назначение). Тогда будет понятнее и какие инструменты лучше использовать в том или ином случае.
Данная статья является попыткой ответить на эти вопросы хотя бы в первом приближении. Материал собирался для себя, но, может, он окажется полезен кому-то еще. Мне данная работа позволила не только узнать много нового, но и в ином контексте взглянуть на кажущиеся уже почти банальными основные принципы ООП и по настоящему оценить их важность.
Информации оказалось довольно много, поэтому приведены лишь общая идея и краткие описания, дающие начальное представление о теме и понимание, где искать дальше.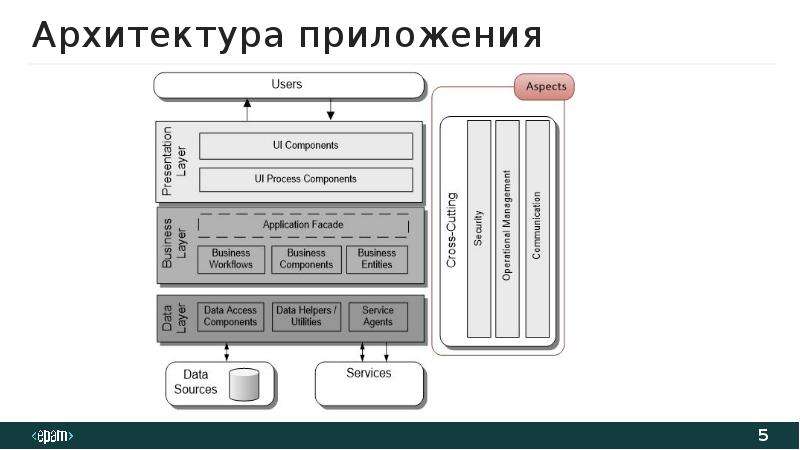
Вообще говоря, не существует общепринятого термина «архитектура программного обеспечения». Тем не менее, когда дело касается практики, то для большинства разработчиков и так понятно какой код является хорошим, а какой плохим.
Хорошая архитектураэто прежде всего
выгоднаяархитектура, делающая процесс разработки и сопровождения программы более простым и эффективным. Программу с хорошей архитектурой легче расширять и изменять, а также тестировать, отлаживать и понимать. То есть, на самом деле можно сформулировать список вполне разумных и универсальных критериев:
Эффективность системы. В первую очередь программа, конечно же, должна решать поставленные задачи и хорошо выполнять свои функции, причем в различных условиях. Сюда можно отнести такие характеристики, как надежность, безопасность, производительность, способность справляться с увеличением нагрузки (масштабируемость) и т.п.
Гибкость системы. Любое приложение приходится менять со временем — изменяются требования, добавляются новые.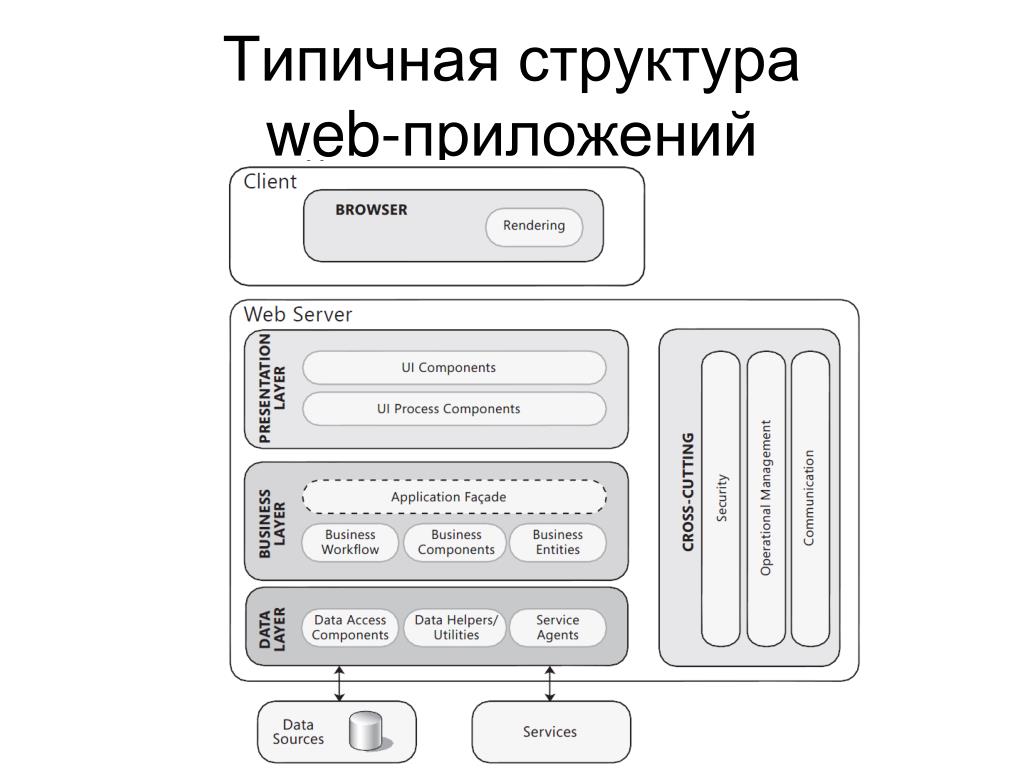 Чем быстрее и удобнее можно внести изменения в существующий функционал, чем меньше проблем и ошибок это вызовет — тем гибче и конкурентоспособнее система. Поэтому в процессе разработки старайтесь оценивать то, что получается, на предмет того, как вам это потом, возможно, придется менять. Спросите у себя: «А что будет, если текущее архитектурное решение окажется неверным?», «Какое количество кода подвергнется при этом изменениям?». Изменение одного фрагмента системы не должно влиять на ее другие фрагменты. По возможности, архитектурные решения не должны «вырубаться в камне», и последствия архитектурных ошибок должны быть в разумной степени ограничены. “ Хорошая архитектура позволяет ОТКЛАДЫВАТЬ принятие ключевых решений” (Боб Мартин) и минимизирует «цену» ошибок.
Чем быстрее и удобнее можно внести изменения в существующий функционал, чем меньше проблем и ошибок это вызовет — тем гибче и конкурентоспособнее система. Поэтому в процессе разработки старайтесь оценивать то, что получается, на предмет того, как вам это потом, возможно, придется менять. Спросите у себя: «А что будет, если текущее архитектурное решение окажется неверным?», «Какое количество кода подвергнется при этом изменениям?». Изменение одного фрагмента системы не должно влиять на ее другие фрагменты. По возможности, архитектурные решения не должны «вырубаться в камне», и последствия архитектурных ошибок должны быть в разумной степени ограничены. “ Хорошая архитектура позволяет ОТКЛАДЫВАТЬ принятие ключевых решений” (Боб Мартин) и минимизирует «цену» ошибок.
Расширяемость системы. Возможность добавлять в систему новые сущности и функции, не нарушая ее основной структуры. На начальном этапе в систему имеет смысл закладывать лишь основной и самый необходимый функционал (принцип YAGNI — you ain’t gonna need it, «Вам это не понадобится») Но при этом архитектура должна позволять легко наращивать дополнительный функционал по мере необходимости. Причем так, чтобы внесение наиболее вероятных изменений требовало наименьших усилии
Причем так, чтобы внесение наиболее вероятных изменений требовало наименьших усилии
Требование, чтобы архитектура системы обладала гибкостью и расширяемостью (то есть была способна к изменениям и эволюции) является настолько важным, что оно даже сформулировано в виде отдельного принципа — «Принципа открытости/закрытости» (Open-Closed Principle — второй из пяти принципов SOLID): Программные сущности (классы, модули, функции и т.п.) должны быть открытыми для расширения, но закрытыми для модификации.
Иными словами: Должна быть возможность расширить/изменить поведение системы без изменения/переписывания уже существующих частей системы.
Это означает, что приложение следует проектировать так, чтобы изменение его поведения и добавление новой функциональности достигалось бы за счет написания нового кода (расширения), и при этом не приходилось бы менять уже существующий код. В таком случае появление новых требований не повлечет за собой модификацию существующей логики, а сможет быть реализовано прежде всего за счет ее расширения.
Масштабируемость процесса разработки. Возможность сократить срок разработки за счёт добавления к проекту новых людей. Архитектура должна позволять распараллелить процесс разработки, так чтобы множество людей могли работать над программой одновременно.
Тестируемость. Код, который легче тестировать, будет содержать меньше ошибок и надежнее работать. Но тесты не только улучшают качество кода. Многие разработчики приходят к выводу, что требование «хорошей тестируемости» является также направляющей силой, автоматически ведущей к хорошему дизайну, и одновременно одним из важнейших критериев, позволяющих оценить его качество: “Используйте принцип «тестируемости» класса в качестве «лакмусовой бумажки» хорошего дизайна класса. Даже если вы не напишите ни строчки тестового кода, ответ на этот вопрос в 90% случаев поможет понять, насколько все «хорошо» или «плохо» с его дизайном
Существует целая методология разработки программ на основе тестов, которая так и называется — Разработка через тестирование (Test-Driven Development, TDD).
Возможность повторного использования. Систему желательно проектировать так, чтобы ее фрагменты можно было повторно использовать в других системах.
Хорошо структурированный, читаемый и понятный код. Сопровождаемость. Над программой, как правило, работает множество людей — одни уходят, приходят новые. После написания сопровождать программу тоже, как правило, приходится людям, не участвовавшем в ее разработке. Поэтому хорошая архитектура должна давать возможность относительно легко и быстро разобраться в системе новым людям. Проект должен быть хорошо структурирован, не содержать дублирования, иметь хорошо оформленный код и желательно документацию. И по возможности в системе лучше применять стандартные, общепринятые решения привычные для программистов. Чем экзотичнее система, тем сложнее ее понять другим ( Принцип наименьшего удивления — Principle of least astonishment. Обычно, он используется в отношении пользовательского интерфейса, но применим и к написанию кода).
Обычно, он используется в отношении пользовательского интерфейса, но применим и к написанию кода).
Ну и для полноты критерии плохого дизайна:
- Его тяжело изменить, поскольку любое изменение влияет на слишком большое количество других частей системы. (Жесткость, Rigidity).
- При внесении изменений неожиданно ломаются другие части системы. (Хрупкость, Fragility
- Код тяжело использовать повторно в другом приложении, поскольку его слишком тяжело «выпутать» из текущего приложения. (Неподвижность, Immobility).
Не смотря на разнообразие критериев, все же главной при разработке больших систем считается задача снижения сложности. А для снижения сложности ничего, кроме деления на части, пока не придумано. Иногда это называют принципом «разделяй и властвуй» (divide et impera), но по сути речь идет об иерархической декомпозиции. Сложная система должна строится из небольшого количества более простых подсистем, каждая из которых, в свою очередь, строится из частей меньшего размера, и т. д., до тех пор, пока самые небольшие части не будут достаточно просты для непосредственного понимания и создания.
д., до тех пор, пока самые небольшие части не будут достаточно просты для непосредственного понимания и создания.
Удача заключается в том, что данное решение является не только единственно известным, но и универсальным. Помимо снижения сложности, оно одновременно обеспечивает гибкость системы, дает хорошие возможности для масштабирования, а также позволяет повышать устойчивость за счет дублирования критически важных частей.
Соответственно, когда речь идет о построении архитектуры программы, создании ее структуры, под этим, главным образом, подразумевается декомпозиция программы на подсистемы (функциональные модули, сервисы, слои, подпрограммы) и организация их взаимодействия друг с другом и внешним миром. Причем, чем более независимы подсистемы, тем безопаснее сосредоточиться на разработке каждой из них в отдельности в конкретный момент времени и при этом не заботиться обо всех остальных частях.
В этом случае программа из «спагетти-кода» превращается в конструктор, состоящий из набора модулей/подпрограмм, взаимодействующих друг с другом по хорошо определенным и простым правилам, что собственно и позволяет контролировать ее сложность, а также дает возможность получить все те преимущества, которые обычно соотносятся с понятием хорошая архитектура:
- Масштабируемость (Scalability)
возможность расширять систему и увеличивать ее производительность, за счет добавления новых модулей.
- Ремонтопригодность (Maintainability)
изменение одного модуля не требует изменения других модулей - Заменимость модулей (Swappability)
модуль легко заменить на другой - Возможность тестирования (Unit Testing)
модуль можно отсоединить от всех остальных и протестировать / починить - Переиспользование (Reusability)
модуль может быть переиспользован в других программах и другом окружении - Сопровождаемость (Maintenance)
разбитую на модули программу легче понимать и сопровождать

Можно сказать, что в разбиении сложной проблемы на простые фрагменты и заключается цель всех методик проектирования. А термином «архитектура», в большинстве случаев, просто обозначают результат такого деления, плюс “
некие конструктивные решения, которые после их принятия с трудом поддаются изменению” (Мартин Фаулер «Архитектура корпоративных программных приложений»). Поэтому большинство определений в той или иной форме сводятся к следующему:
Поэтому большинство определений в той или иной форме сводятся к следующему:
“Архитектура идентифицирует главные компоненты системы и способы их взаимодействия. Также это выбор таких решений, которые интерпретируются как основополагающие и не подлежащие изменению в будущем.“
“Архитектура — это организация системы, воплощенная в ее компонентах, их отношениях между собой и с окружением.
Система — это набор компонентов, объединенных для выполнения определенной функции.“
Таким образом, хорошая архитектура это, прежде всего, модульная/блочная архитектура. Чтобы получить хорошую архитектуру надо знать, как правильно делать декомпозицию системы. А значит, необходимо понимать — какая декомпозиция считается «правильной» и каким образом ее лучше проводить?
1. Иерархическая
Не стоит сходу рубить приложение на сотни классов. Как уже говорилось, декомпозицию надо проводить иерархически — сначала систему разбивают на крупные функциональные модули/подсистемы, описывающие ее работу в самом общем виде. Затем, полученные модули, анализируются более детально и, в свою очередь, делятся на под-модули либо на объекты.
Как уже говорилось, декомпозицию надо проводить иерархически — сначала систему разбивают на крупные функциональные модули/подсистемы, описывающие ее работу в самом общем виде. Затем, полученные модули, анализируются более детально и, в свою очередь, делятся на под-модули либо на объекты.
Перед тем как выделять объекты разделите систему на основные смысловые блоки хотя бы мысленно. Для небольших приложений двух уровней иерархии часто оказывается вполне достаточно — система вначале делится на подсистемы/пакеты, а пакеты делятся на классы.
Эта мысль, при всей своей очевидности, не так банальна как кажется. Например, в чем заключается суть такого распространенного «архитектурного шаблона» как Модель-Вид-Контроллер (MVC)? Всего навсего в отделении представления от бизнес-логики, то есть в том, что любое пользовательское приложение вначале делится на два модуля — один из которых отвечает за реализацию собственно самой бизнес логики (Модель), а второй — за взаимодействие с пользователем (Пользовательский Интерфейс или Представление). Затем, для того чтобы эти модули могли разрабатываться независимо, связь между ними ослабляется с помощью паттерна «Наблюдатель» (подробно о способах ослабления связей будет рассказано дальше) и мы фактически получаем один из самых мощных и востребованных «шаблонов», которые используются в настоящее время.
Затем, для того чтобы эти модули могли разрабатываться независимо, связь между ними ослабляется с помощью паттерна «Наблюдатель» (подробно о способах ослабления связей будет рассказано дальше) и мы фактически получаем один из самых мощных и востребованных «шаблонов», которые используются в настоящее время.
Типичными модулями первого уровня (полученными в результате первого деления системы на наиболее крупные составные части) как раз и являются — «бизнес-логика», «пользовательский интерфейс», «доступ к БД», «связь с конкретным оборудованием или ОС».
Для обозримости на каждом иерархическом уровне рекомендуют выделять от 2 до 7 модулей.
2. Функциональная
Деление на модули/подсистемы лучше всего производить исходя из тех задач, которые решает система. Основная задача разбивается на составляющие ее подзадачи, которые могут решаться/выполняться независимо друг от друга. Каждый модуль должен отвечать за решение какой-то подзадачи и выполнять соответствующую ей функцию. Помимо функционального назначения модуль характеризуется также набором данных, необходимых ему для выполнения его функции, то есть:
Помимо функционального назначения модуль характеризуется также набором данных, необходимых ему для выполнения его функции, то есть:
Модуль = Функция + Данные, необходимые для ее выполнения.
Причем желательно, чтобы свою функцию модуль мог выполнить самостоятельно, без помощи остальных модулей, лишь на основе своих входящих данных.
Модуль — это не произвольный кусок кода, а отдельная функционально осмысленная и законченная программная единица (подпрограмма), которая обеспечивает решение некоторой задачи и в идеале может работать самостоятельно или в другом окружении и быть переиспользуемой. Модуль должен быть некой “целостностью, способной к относительной самостоятельности в поведении и развитии” (Кристофер Александер).
Таким образом, грамотная декомпозиция основывается, прежде всего, на анализе функций системы и необходимых для выполнения этих функций данных.
3. High Cohesion + Low Coupling
Самым же главным критерием качества декомпозиции является то, насколько модули сфокусированы на решение своих задач и независимы. Обычно это формулируют следующим образом: “Модули, полученные в результате декомпозиции, должны быть максимально сопряженны внутри (high internal cohesion) и минимально связанны друг с другом (low external coupling).“
Обычно это формулируют следующим образом: “Модули, полученные в результате декомпозиции, должны быть максимально сопряженны внутри (high internal cohesion) и минимально связанны друг с другом (low external coupling).“
- High Cohesion, высокая сопряженность или «сплоченность» внутри модуля, говорит о том, модуль сфокусирован на решении одной узкой проблемы, а не занимается выполнением разнородных функций или несвязанных между собой обязанностей. (Сопряженность — cohesion, характеризует степень, в которой задачи, выполняемые модулем, связаны друг с другом )
Следствием High Cohesion является принцип единственной ответственности (Single Responsibility Principle — первый из пяти принципов SOLID), согласно которому любой объект/модуль должен иметь лишь одну обязанность и соответственно не должно быть больше одной причины для его изменения.
- Low Coupling, слабая связанность, означает что модули, на которые разбивается система, должны быть, по возможности, независимы или слабо связанны друг с другом. Они должны иметь возможность взаимодействовать, но при этом как можно меньше знать друг о друге (принцип минимального знания).
Это значит, что при правильном проектировании, при изменении одного модуля, не придется править другие или эти изменения будут минимальными. Чем слабее связанность, тем легче писать/понимать/расширять/чинить программу.
 Они должны иметь возможность взаимодействовать, но при этом как можно меньше знать друг о друге (принцип минимального знания).
Они должны иметь возможность взаимодействовать, но при этом как можно меньше знать друг о друге (принцип минимального знания).Считается, что хорошо спроектированные модули должны обладать следующими свойствами:
- функциональная целостность и завершенность — каждый модуль реализует одну функцию, но реализует хорошо и полностью; модуль самостоятельно (без помощи дополнительных средств) выполняет полный набор операций для реализации своей функции.
- один вход и один выход — на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO — вход–процесс–выход;
- логическая независимость — результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей;
- слабые информационные связи с другими модулями — обмен информацией между модулями должен быть по возможности минимизирован.

Грамотная декомпозиция — это своего рода искусство и гигантская проблема для многих программистов. Простота тут очень обманчива, а ошибки обходятся очень дорого. Если выделенные модули оказываются сильно сцеплены друг с другом, если их не удается разрабатывать независимо или не ясно за какую конкретно функцию каждый из них отвечает, то стоит задуматься а правильно ли вообще производится деление. Должно быть понятно, какую роль выполняет каждый модуль. Самый же надежный критерий того, что декомпозиция делается правильно, это если модули получаются самостоятельными и ценными сами по себе подпрограммами, которые могут быть использованы в отрыве от всего остального приложения (а значит, могут быть переиспользуемы).
Делая декомпозицию системы желательно проверять ее качество задавая себе вопросы: “Какую функцию выполняет каждый модуль?“, “Насколько модули легко тестировать?”, “Возможно ли использовать модули самостоятельно или в другом окружении?”, “Как сильно изменения в одном модуле отразятся на остальных?”
В первую очередь следует, конечно же, стремиться к тому, чтобы модули были предельно автономны. Как и было сказано, это является ключевым параметром правильной декомпозиции. Поэтому проводить ее нужно таким образом, чтобы модули изначально слабо зависели друг от друга. Но кроме того, имеется ряд специальных техник и шаблонов, позволяющих затем дополнительно минимизировать и ослабить связи между подсистемами. Например, в случае MVC для этой цели использовался шаблон «Наблюдатель», но возможны и другие решения. Можно сказать, что техники для уменьшения связанности, как раз и составляют основной «инструментарий архитектора». Только необходимо понимать, что речь идет о всех подсистемах и ослаблять связанность нужно на всех уровнях иерархии, то есть не только между классам, но также и между модулями на каждом иерархическом уровне.
Как и было сказано, это является ключевым параметром правильной декомпозиции. Поэтому проводить ее нужно таким образом, чтобы модули изначально слабо зависели друг от друга. Но кроме того, имеется ряд специальных техник и шаблонов, позволяющих затем дополнительно минимизировать и ослабить связи между подсистемами. Например, в случае MVC для этой цели использовался шаблон «Наблюдатель», но возможны и другие решения. Можно сказать, что техники для уменьшения связанности, как раз и составляют основной «инструментарий архитектора». Только необходимо понимать, что речь идет о всех подсистемах и ослаблять связанность нужно на всех уровнях иерархии, то есть не только между классам, но также и между модулями на каждом иерархическом уровне.
Для наглядности, картинка из неплохой статьи “
Decoupling of Object-Oriented Systems“, иллюстрирующая основные моменты, о которых будет идти речь.
1. Интерфейсы. Фасад
Главным, что позволяет уменьшать связанность системы, являются конечно же
Интерфейсы(и стоящий за ними принцип
Инкапсуляция + Абстракция + Полиморфизм):
- Модули должны быть друг для друга “черными ящиками” (инкапсуляция). Это означает, что один модуль не должен «лезть» внутрь другого модуля и что либо знать о его внутренней структуре. Объекты одной подсистемы не должны обращаться напрямую к объектам другой подсистемы
- Модули/подсистемы должны взаимодействовать друг с другом лишь посредством интерфейсов (то есть, абстракций, не зависящих от деталей реализации) Соответственно каждый модуль должен иметь четко определенный интерфейс или интерфейсы для взаимодействия с другими модулями.
 Это означает, что один модуль не должен «лезть» внутрь другого модуля и что либо знать о его внутренней структуре. Объекты одной подсистемы не должны обращаться напрямую к объектам другой подсистемы
Это означает, что один модуль не должен «лезть» внутрь другого модуля и что либо знать о его внутренней структуре. Объекты одной подсистемы не должны обращаться напрямую к объектам другой подсистемыПринцип «черного ящика» (
инкапсуляция) позволяет рассматривать структуру каждой подсистемы независимо от других подсистем. Модуль, представляющий собой черный ящик, можно относительно свободно менять. Проблемы могут возникнуть лишь на стыке разных модулей (или модуля и окружения). И вот это взаимодействие нужно описывать в максимально общей (
абстрактной) форме — в форме интерфейса. В этом случае код будет работать одинаково с любой реализацией, соответствующей контракту интерфейса. Собственно именно эта возможность работать с различными реализациями (модулями или объектами) через унифицированный интерфейс и называется полиморфизмом. Полиморфизм это вовсе не переопределение методов, как иногда ошибочно полагают, а прежде всего —
Собственно именно эта возможность работать с различными реализациями (модулями или объектами) через унифицированный интерфейс и называется полиморфизмом. Полиморфизм это вовсе не переопределение методов, как иногда ошибочно полагают, а прежде всего —
модулей/объектов с одинаковым интерфейсом, или «один интерфейс, множество реализаций» (подробнее
тут). Для реализации полиморфизма механизм наследования совсем не нужен. Это важно понимать, поскольку наследования вообще, по возможности, следует избегать.
Благодаря интерфейсам и полиморфизму, как раз и достигается возможность модифицировать и расширять код, без изменения того, что уже написано (Open-Closed Principle). До тех пор, пока взаимодействие модулей описано исключительно в виде интерфейсов, и не завязано на конкретные реализации, мы имеем возможность абсолютно «безболезненно» для системы заменить один модуль на любой другой, реализующий тот же самый интерфейс, а также добавить новый и тем самым расширить функциональность. Это как в конструкторе или «плагинной архитектуре» (plugin architecture) — интерфейс служит своего рода коннектором, куда может быть подключен любой модуль с подходящим разъемом. Гибкость конструктора обеспечивается тем, что мы можем просто заменить одни модули/«детали» на другие, с такими же разъемами (с тем же интерфейсом), а также добавить сколько угодно новых деталей (при этом уже существующие детали никак не изменяются и не переделываются). Подробнее про Open-Closed Principle и про то, как он может быть реализован можно почитать тут + хорошая статья на английском.
Это как в конструкторе или «плагинной архитектуре» (plugin architecture) — интерфейс служит своего рода коннектором, куда может быть подключен любой модуль с подходящим разъемом. Гибкость конструктора обеспечивается тем, что мы можем просто заменить одни модули/«детали» на другие, с такими же разъемами (с тем же интерфейсом), а также добавить сколько угодно новых деталей (при этом уже существующие детали никак не изменяются и не переделываются). Подробнее про Open-Closed Principle и про то, как он может быть реализован можно почитать тут + хорошая статья на английском.
Интерфейсы позволяют строить систему более высокого уровня, рассматривая каждую подсистему как единое целое и игнорируя ее внутреннее устройство. Они дают возможность модулям взаимодействовать и при этом ничего не знать о внутренней структуре друг друга, тем самым в полной мере реализуя принцип минимального знания, являющейся основой слабой связанности. Причем, чем в более общей/абстрактной форме определены интерфейсы и чем меньше ограничений они накладывают на взаимодействие, тем гибче система. Отсюда фактически следует еще один из принципов SOLID — Принцип разделения интерфейса (Interface Segregation Principle), который выступает против «толстых интерфейсов» и говорит, что большие, объемные интерфейсы надо разбивать на более маленькие и специфические, чтобы клиенты маленьких интерфейсов (зависящие модули) знали только о методах, которые необходимы им в работе. Формулируется он следующим образом: “Клиенты не должны зависеть от методов (знать о методах), которые они не используют” или “Много специализированных интерфейсов лучше, чем один универсальный”.
Отсюда фактически следует еще один из принципов SOLID — Принцип разделения интерфейса (Interface Segregation Principle), который выступает против «толстых интерфейсов» и говорит, что большие, объемные интерфейсы надо разбивать на более маленькие и специфические, чтобы клиенты маленьких интерфейсов (зависящие модули) знали только о методах, которые необходимы им в работе. Формулируется он следующим образом: “Клиенты не должны зависеть от методов (знать о методах), которые они не используют” или “Много специализированных интерфейсов лучше, чем один универсальный”.
Итак, когда взаимодействие и зависимости модулей описываются лишь с помощью интерфейсов, те есть абстракций, без использования знаний об их внутреннем устройстве и структуре, то фактически тем самым реализуется инкапсуляция, плюс мы имеем возможность расширять/изменять поведения системы за счет добавления и использования различных реализаций, то есть за счет полиморфизма. Из этого следует, что концепция интерфейсов включает в себя и в некотором смысле обобщает почти все основные принципы ООП — Инкапсуляцию, Абстракцию, Полиморфизм. Но тут возникает один вопрос. Когда проектирование идет не на уровне объектов, которые сами же и реализуют соответствующие интерфейсы, а на уровне модулей, то что является реализацией интерфейса модуля? Ответ: если говорить языком шаблонов, то как вариант, за реализацию интерфейса модуля может отвечать специальный объект — Фасад.
Из этого следует, что концепция интерфейсов включает в себя и в некотором смысле обобщает почти все основные принципы ООП — Инкапсуляцию, Абстракцию, Полиморфизм. Но тут возникает один вопрос. Когда проектирование идет не на уровне объектов, которые сами же и реализуют соответствующие интерфейсы, а на уровне модулей, то что является реализацией интерфейса модуля? Ответ: если говорить языком шаблонов, то как вариант, за реализацию интерфейса модуля может отвечать специальный объект — Фасад.
Фасад — это объект-интерфейс, аккумулирующий в себе высокоуровневый набор операций для работы с некоторой подсистемой, скрывающий за собой ее внутреннюю структуру и истинную сложность. Обеспечивает защиту от изменений в реализации подсистемы. Служит единой точкой входа — “вы пинаете фасад, а он знает, кого там надо пнуть в этой подсистеме, чтобы получить нужное”.
Таким образом, мы получаем первый, самый важный паттерн, позволяющий использовать концепцию интерфейсов при проектировании модулей и тем самым ослаблять их связанность — «Фасад». Помимо этого «Фасад» вообще дает возможность работать с модулями точно также как с обычными объектами и применять при проектировании модулей все те полезные принципы и техники, которые используются при проектирования классов.
Помимо этого «Фасад» вообще дает возможность работать с модулями точно также как с обычными объектами и применять при проектировании модулей все те полезные принципы и техники, которые используются при проектирования классов.
Замечание: Хотя большинство программистов понимают важность интерфейсов при проектировании классов (объектов), складывается впечатление, что идея необходимости использовать интерфейсы также и на уровне модулей только зарождается. Мне встретилось очень мало статей и проектов, где интерфейсы бы применялись для ослабления связанности между модулями/слоями и соответственно использовался бы паттерн «Фасад». Кто, например, видел «Фасад» на схемах уже упоминавшегося «архитектурного шаблона» Модель-Вид-Контроллер, или хотя бы слышал его упоминание среди паттернов, входящих в состав MVC (наряду с Observer и Composite)? А ведь он там должен быть, поскольку Модель это не класс, это модуль, причем центральный. И у создателя MVC Трюгве Реенскауга он, конечно же, был (смотрим «The Model-View-Controller (MVC ). Its Past and Present», только учитываем, что это писалось в 1973 году и то, что мы сейчас называем Представлением — Presentaition/UI тогда называлось Editior). Странным образом «Фасад» потерялся на многие годы и вновь обнаружить его мне удалось лишь недавно, в основном, в обобщенном варианте MVC от Microsoft («Microsoft Application Architecture Guide»). Вот соответствующие слайды:
Its Past and Present», только учитываем, что это писалось в 1973 году и то, что мы сейчас называем Представлением — Presentaition/UI тогда называлось Editior). Странным образом «Фасад» потерялся на многие годы и вновь обнаружить его мне удалось лишь недавно, в основном, в обобщенном варианте MVC от Microsoft («Microsoft Application Architecture Guide»). Вот соответствующие слайды:
А разработчикам, к сожалению, приходится заново «переоткрывать» идею, что к объектам Модели, отвечающей за бизнес-логику приложения, нужно обращаться не напрямую а через интерфейс, то есть «Фасад», как например, в этой статье, откуда для полноты картины взят еще один слайд:
2. Dependency Inversion. Корректное создание и получение зависимостей
Формально, требование, чтобы модули не содержали ссылок на конкретные реализации, а все зависимости и взаимодействие между ними строились исключительно на основе абстракций, то есть интерфейсов, выражается принципом
Инвертирования зависимостей(
Dependency Inversion— последний из пяти принципов SOLID):
- Модули верхнего уровня не должны зависеть от модулей нижнего уровня. И те, и другие должны зависеть от абстракций.
- Абстракции не должны зависеть от деталей. Реализация должна зависеть от абстракции.
У этого принципа не самая очевидная формулировка, но суть его, как и было сказано, выражается правилом: «
Все зависимости должны быть в виде интерфейсов». Подробно и очень хорошо принцип инвертирования зависимостей разбирается в статье
Модульный дизайн или «что такое DIP, SRP, IoC, DI и т.п.». Статья из разряда must-read, лучшее, что доводилось читать по архитектуре ПО.
Не смотря на свою фундаментальность и кажущуюся простоту это правило нарушается, пожалуй, чаще всего. А именно, каждый раз, когда в коде программы/модуля мы используем оператор new и создаем новый объект конкретного типа, то тем самым вместо зависимости от интерфейса образуется зависимость от реализации.
Понятно, что этого нельзя избежать и объекты где-то должны создаваться. Но, по крайней мере, нужно свести к минимуму количество мест, где это делается и в которых явно указываются классы, а также локализовать и изолировать такие места, чтобы они не были разбросаны по всему коду программы. Решение заключается в том, чтобы сконцентрировать создание новых объектов в рамках специализированных объектов и модулей — фабрик, сервис локаторов, IoC-контейнеров.
В каком-то смысле такое решение следует Принципу единственного выбора (Single Choice Principle), который говорит: “всякий раз, когда система программного обеспечения должна поддерживать множество альтернатив, их полный список должен быть известен только одному модулю системы“. В этом случае, если в будущем придется добавить новые варианты (или новые реализации, как в рассматриваемом нами случае создания новых объектов), то достаточно будет произвести обновление только того модуля, в котором содержится эта информация, а все остальные модули останутся незатронутыми и смогут продолжать свою работу как обычно.
Ну а теперь разберем подробнее, как это делается на практике и каким образом модули могут корректно создавать и получать свои «зависимости», не нарушая принципа Dependency Inversion.
Итак, при проектировании модуля должны быть определены следующие ключевые вещи:
- что модуль делает, какую функцию выполняет
- что модулю нужно от его окружения, то есть с какими объектами/модулями ему придется иметь дело и
- как он это будет получать
Крайне важно то,
как модуль получает ссылки на объекты, которые он использует в своей работе. И тут возможны следующие варианты:
- Модуль сам создает объекты необходимые ему для работы.
Но, как и было сказано, модуль не может это сделать напрямую — для создания необходимо вызвать конструктор конкретного типа, и в результате модуль будет зависеть не от интерфейса, а от конкретной реализации. Решить проблему в данном случае позволяет шаблон Фабричный Метод (Factory Method).
“Суть заключается в том, что вместо непосредственного инстанцирования объекта через new, мы предоставляем классу-клиенту некоторый интерфейс для создания объектов. Поскольку такой интерфейс при правильном дизайне всегда может быть переопределён, мы получаем определённую гибкость при использовании низкоуровневых модулей в модулях высокого уровня”.
В случаях, когда нужно создавать группы или семейства взаимосвязанных объектов, вместо Фабричного Метода используется Абстрактная Фабрика (Abstract factory).
- Модуль берет необходимые объекты у того, у кого они уже есть (обычно это некоторый, известный всем репозиторий, в котором уже лежит все, что только может понадобиться для работы программы).
Этот подход реализуется шаблоном Локатор Сервисов (Service Locator), основная идея которого заключается в том, что в программе имеется объект, знающий, как получить все зависимости (сервисы), которые могут потребоваться.
Главное отличие от фабрик в том, что Service Locator не создаёт объекты, а фактически уже содержит в себе инстанцированные объекты (или знает где/как их получить, а если и создает, то только один раз при первом обращении). Фабрика при каждом обращении создает новый объект, который вы получаете в полную собственность и можете делать с ним что хотите. Локатор же сервисов выдает ссылки на одни и те же, уже существующие объекты. Поэтому с объектами, выданными Service Locator, нужно быть очень осторожным, так как одновременно с вами ими может пользоваться кто-то еще.
Объекты в Service Locator могут быть добавлены напрямую, через конфигурационный файл, да и вообще любым удобным программисту способом. Сам Service Locator может быть статическим классом с набором статических методов, синглетоном или интерфейсом и передаваться требуемым классам через конструктор или метод.
Вообще говоря, Service Locator иногда называют антипаттерном и не рекомендуют использовать (главным образом потому, что он создает неявные связности и дает лишь видимость хорошего дизайна). Подробно можно почитать у Марка Симана:
Service Locator is an Anti-Pattern
Abstract Factory or Service Locator? - Модуль вообще не заботиться о «добывании» зависимостей. Он лишь определяет, что ему нужно для работы, а все необходимые зависимости ему поставляются («впрыскиваются») из вне кем-то другим.
Это так и называется — Внедрение Зависимостей (Dependency Injection). Обычно требуемые зависимости передаются либо в качестве параметров конструктора (Constructor Injection), либо через методы класса (Setter injection).
Такой подход инвертирует процесс создания зависимости — вместо самого модуля создание зависимостей контролирует кто-то извне. Модуль из активного элемента, становится пассивным — не он делает, а для него делают. Такое изменение направления действия называется Инверсия Контроля (Inversion of Control), или Принцип Голливуда — «Не звоните нам, мы сами вам позвоним».
Это самое гибкое решение, дающее модулям наибольшую автономность. Можно сказать, что только оно в полной мере реализует «Принцип единственной ответственности» — модуль должен быть полностью сфокусирован на том, чтобы хорошо выполнять свою функцию и не заботиться ни о чем другом. Обеспечение его всем необходимым для работы это отдельная задача, которой должен заниматься соответствующий «специалист» (обычно управлением зависимостями и их внедрениями занимается некий контейнер — IoC-контейнер).
По сути, здесь все как в жизни: в хорошо организованной компании программисты программируют, а столы, компьютеры и все необходимое им для работы покупает и обеспечивает кладовщик. Или, если использовать метафору программы как конструктора — модуль не должен думать о проводах, сборкой конструктора занимается кто-то другой, а не сами детали.
Более подробно и с примерами о способах создания и получения зависимостей можно почитать, например, в этой
статье(только надо иметь ввиду, что хотя автор пишет о
Dependency Inversion, он использует термин
Inversion of Control; возможно потому, что в русской википедии содержится ошибка и этим терминам даны одинаковые определения). А принцип
Inversion of Control(вместе с
Dependency Injectionи
Service Locator) детально разбирается Мартином Фаулером и есть переводы обеих его статей: “
Inversion of Control Containers and the Dependency Injection pattern” и “
Inversion of Control”.
Не будет преувеличением сказать, что использование интерфейсов для описания зависимостей между модулями (Dependency Inversion) + корректное создание и внедрение этих зависимостей (прежде всего Dependency Injection) являются центральными/базовыми техниками для снижения связанности. Они служат тем фундаментом, на котором вообще держится слабая связанность кода, его гибкость, устойчивость к изменениям, переиспользование, и без которого все остальные техники имеют мало смысла. Но, если с фундаментом все в порядке, то знание дополнительных приемов может быть очень даже полезным. Поэтому продолжим.
3. Замена прямых зависимостей на обмен сообщениями
Иногда модулю нужно всего лишь
известитьдругих о том, что в нем произошли какие-то события/изменения и ему не важно, что с этой информацией будет происходить потом. В этом случае модулям вовсе нет необходимости «знать друг о друге», то есть содержать прямые ссылки и взаимодействовать непосредственно, а достаточно всего лишь обмениваться сообщениями (messages) или событиями (events).
Связь модулей через обмен сообщениями является гораздо более слабой, чем прямая зависимость и реализуется она чаще всего с помощью следующих шаблонов:
- Наблюдатель (Observer). Применяется в случае зависимости «один-ко-многим», когда множество модулей зависят от состояния одного — основного. Использует механизм рассылки, который заключается в том, что основной модуль просто осуществляет рассылку одинаковых сообщений всем своим подписчикам, а модули, заинтересованные в этой информации, реализуют интерфейс «подписчика» и подписываются на рассылку. Находит широкое применение в системах с пользовательским интерфейсом, позволяя ядру приложения (модели) оставаться независимым и при этом информировать связанные с ним интерфейсы о том что произошли какие-то изменения и нужно обновиться.
Организация взаимодействия посредством рассылки сообщений имеет дополнительный «бонус» — необязательность существования «подписчиков» на «опубликованные» (т.е. рассылаемые) сообщения. Качественно спроектированная подобная система допускает добавление/удаление модулей в любое время.
- Посредник (Mediator). Применяется, когда между модулями имеется зависимость «многие ко многим. Медиатор выступает в качестве посредника в общении между модулями, действуя как центр связи и избавляет модули от необходимости явно ссылаться друг на друга. В результате взаимодействие модулей друг с другом («все со всеми») заменяется взаимодействием модулей лишь с посредником («один со всеми»). Говорят, что посредник инкапсулирует взаимодействие между множеством модулей.
Типичный пример — контроль трафика в аэропорту. Все сообщения, исходящие от самолетов, поступают в башню управления диспетчеру, вместо того, чтобы пересылаться между самолетами напрямую. А диспетчер уже принимает решения о том, какие самолеты могут взлетать или садиться, и в свою очередь отправляет самолетам соответствующие сообщения. Подробнее, например, тут.
Дополнение: Модули могут пересылать друг другу не только «простые сообщения, но и объекты-команды. Такое взаимодействие описывается шаблономКоманда
(
Command).
Суть заключается в инкапсулировании запроса на выполнение определенного действия в виде отдельного объекта (фактически этот объект содержит один единственный метод execute()), что позволяет затем передавать это действие другим модулям на выполнение в качестве параметра, и вообще производить с объектом-командой любые операции, какие могут быть произведены над обычными объектами. Кратко рассмотрентут, соответствующая глава из книги банды четырехтут, есть также статья нахабре.4. Замена прямых зависимостей на синхронизацию через общее ядро
Данный подход обобщает и развивает идею заложенную в шаблоне «Посредник». Когда в системе присутствует большое количество модулей, их прямое взаимодействие друг с другом становится слишком сложным. Поэтому имеет смысл взаимодействие «все со всеми» заменить на взаимодействие «один со всеми». Для этого вводится некий обобщенный посредник, это может быть общее ядро приложения, хранилище или шина данных, а все остальные модули становятся независимыми друг от друга клиентами, использующими сервисы этого ядра или выполняющими обработку содержащейся там информации. Реализация этой идеи позволяет модулям-клиентам общаться друг с другом через посредника и при этом ничего друг о друге не знать.
Ядро-посредник может как знать о модулях-клиентах и управлять ими (пример — архитектура apache ), так и может быть полностью, или почти полностью, независимым и ничего о клиентах не знать. В сущности именно этот подход реализован в «шаблоне» Модель-Вид-Контроллер (MVC), где с одной Моделью (являющейся ядром приложение и общим хранилищем данных) могут взаимодействовать множество Пользовательских Интерфейсов, которые работают синхронно и при этом не знают друг о друге, а Модель не знает о них. Ничто не мешает подключить к общей модели и синхронизировать таким образом не только интерфейсы, но и другие вспомогательные модули.
Очень активно эта идея также используется при разработке игр, где независимые модули, отвечающие за графику, звук, физику, управление программой синхронизируются друг с другом через игровое ядро (модель), где хранятся все данные о состоянии игры и ее персонажах. В отличие от MVC, в играх согласование модулей с ядром (моделью) происходит не за счет шаблона «Наблюдатель», а по таймеру, что само по себе является интересным архитектурным решением весьма полезным для программ с анимацией и «бегущей» графикой.
5. Закон Деметры (law of Demeter)
Закон Деметры
запрещает использование неявных зависимостей: “
Объект A не должен иметь возможность получить непосредственный доступ к объекту C, если у объекта A есть доступ к объекту B и у объекта B есть доступ к объекту C“.
Java-пример.
Это означает, что все зависимости в коде должны быть «явными» — классы/модули могут использовать в работе только «свои зависимости» и не должны лезть через них к другим. Кратко этот принцип формулируют еще таким образом: “Взаимодействуй только с непосредственными друзьями, а не с друзьями друзей“. Тем самым достигается меньшая связанность кода, а также большая наглядность и прозрачность его дизайна.
Закон Деметры реализует уже упоминавшийся «принцип минимального знания», являющейся основой слабой связанности и заключающийся в том, что объект/модуль должен знать как можно меньше деталей о структуре и свойствах других объектов/модулей и вообще чего угодно, включая собственные подкомпоненты. Аналогия из жизни: Если Вы хотите, чтобы собака побежала, глупо командовать ее лапами, лучше отдать команду собаке, а она уже разберётся со своими лапами сама.
6. Композиция вместо наследования
Одну из самых сильных связей между объектами дает наследование, поэтому, по возможности, его следует избегать и заменять композицией. Эта тема хорошо раскрыта в статье Герба Саттера — «
Предпочитайте композицию наследованию».
Могу только посоветовать в данном контексте обратить внимание на шаблон Делегат (Delegation/Delegate) и пришедший из игр шаблон Компонет (Component), который подробно описан в книге «Game Programming Patterns» (соответствующая глава из этой книги на английском и ее перевод).
Статьи в интернете:
Замечательный ресурс —
Архитектура приложений с открытым исходным кодом, где “
авторы четырех дюжин приложений с открытым исходным кодом рассказывают о структуре созданных ими программ и о том, как эти программы создавались. Каковы их основные компоненты? Как они взаимодействуют? И что открыли для себя их создатели в процессе разработки? В ответах на эти вопросы авторы статей, собранных в данных книгах, дают вам уникальную возможность проникнуть в то, как они творят“. Одна из статей полностью была опубликована на хабре — «
Масштабируемая веб-архитектура и распределенные системы».
Интересные решения и идеи можно найти в материалах, посвященных разработке игр. Game Programming Patterns — большой сайт с подробным описанием многих шаблонов и примерами их применения к задаче создания игр (оказывается, есть уже его перевод — «Шаблоны игрового программирования», спасибо strannik_k за ссылку). Возможно будет полезна также статья «Гибкая и масштабируемая архитектура для компьютерных игр» (и ее оригинал. Нужно только иметь ввиду что автор почему-то композицию называет шаблоном “Наблюдатель”).
По поводу паттернов проектирования:
Есть еще принципы/паттерны GRASP, описанные Крэгом Лэрманом в книге «
Применение UML 2.0 и шаблонов проектирования», но они больше запутывают чем проясняют. Краткий обзор и обсуждение на
хабре(самое ценное в комментариях).
Ну и конечно же книги:
Модульная архитектура и многоразовый код / Хабр
Меня всегда интересовала разработка многоразового и целостного кода. Но проблема многоразового кода начинается на этапе переноса в другую инфраструктуру. Если приложение расширяется плагинами, то плагины пишутся под конкретное приложение. А что если вынести логику приложения в плагин (далее — модуль), а интерфейс приложения из управляющего звена превратить в управляемый модулем компонент. На мой взгляд, самая главная задача в подобном сценарии, упростить базовые интерфейсы до минимума и дать возможность переписать или расширить любой фрагмент всей инфраструктуры в отдельности. Если интересно, что вышло из идеи модульного кода, то добро пожаловать под кат.
Идея
Первое условие к предстоящей системе — возможность динамически расширять систему без необходимости перекомпиляции отдельных модулей. Это относится как к хосту, так и к модулям.
Любое звено решения (кроме базовых интерфейсов) может быть переписано и динамически интегрировано. В довесок к возможности расширения модулей интерфейсами, хотелось иметь возможность получать динамический доступ к публичным методам, свойствам и событиям, которые доступны в любом модуле. Соответственно, все элементы класса реализующего базовый интерфейс IPlugin, которые помечены доступностью как public, должны быть видимы извне другими модулями.
Любой модуль, может изыматься и добавляться в инфраструктуру, но при этом, при решении заменить один модуль другим модулем, придётся реализовать всю функциональность удаляемого модуля. Т.е. Модули идентифицируются через атрибут AssemblyGuidAttribute, добавляемый автоматом при создании проекта. Поэтому 2 модуля с одним идентификатором не загрузятся
Каждый модуль должен быть легковесным, чтобы базовые интерфейсы не нуждались в постоянном обновлении, а при необходимости, модуль можно изъять из системы и встроить как обычную сборку в приложение через ссылку (Reference). Благо, CLR загружает зависящие сборки через ленивую загрузку (LazyLoad), так что нужда в сборках модульной инфраструктуры отпадает.
И последнее условие, система должна предоставлять поэтапное раширение функциональности для разработчика, чтобы уровень вхождения был на достаточно низком уровне.
При этом, система должна автоматизировать рутинные задачи, которые повторяются от приложения к приложению. А именно:
- Сохранение/загрузка пользовательских настроек или общее хранилище настроек,
- Сохранение состояния или других параметров, в зависимости от применения,
- Перенос ранее написанных компонентов,
- Ограничение в использовании программного обеспечения без достаточного уровня прав (Загружать компоненты от уровня доступа, а не скрывать элементы интерфейса),
- Взаимодействие с облачной инфраструктурой без необходимости дорабатывать логику (Message Queue, REST, SOAP сервисы, Web sockets, Caching, OAuth/OpenId/OpenId Connect…)
Решение
В результате накопившихся решений и отдельных компонентов, работающих по единому принципу, было составлено общее видение всей инфраструктуры:
- Минимальные требования к основным интерфейсам,
- Модульная инфраструктура с независимым источником загрузки модулей,
- Общее хранилище настроек,
- Независимость решения от реализации приложений (UI, Services):
- Какие хосты есть на момент написания:
- Какие хосты есть на момент написания:
Для предоставления независимости разработки как от конкретного приложения, так и самими программами, появились следующие ключевые компоненты:
- SAL Interfaces — Сборки с базовыми интерфейсами и интерфейсами расширений
- Host — Приложение. (в случае использования в Visual Studio — EnvDTE Add-In), который зависит от версии запускающего приложения,
- Plugin — В основе своей это независимый модуль (плагин) для хоста, но может зависеть от других модулей или реализовать в себе основу для группы других модулей. Кроме обычных плагинов, которые выполняют свои собственные задачи, присутствует 3 типа плагина, которые активно используются самим хостом:
- LoaderProvider — Провайдер, который позволяет подгружать другие модули из разных источников. Я для тестов написал загрузчик из файловой системы в память (Не работает с Managed C++), загрузкой по сети исходя из роли пользователя (Сервер написан под конкретную задачу). Но это не передел, текущая архитектура позволяет использовать в качестве источника как, к примеру, nuget.org, так и удалённое общение с хостом развёрнутым на другой машине.
- SettingsProvider — Провайдер, который отвечает за сохранение и загрузку настроек плагинов. Как я писал выше, по умолчанию написанные хосты используют XML для сохранения и загрузки данных, но это не ограничивает дальнейшее развитие. В готовых модулях я привёл в ккчестве примера провайдер использующий MSSQL.
- Kernel — Ядро бизнес-логики и массива зависимых модулей. По своей сути, является не только основой для зависимых модулей, но и идентификацией приложения для хоста (В минимуме, для идентификации в SettingsProvider, ибо в одном хосте могут запускаться разные массивы модулей, объединённые разными Kernel модулями).
Готовые базовые сборки
В результате этих требований сформировались следующие базовые сборки:
- SAL.Core — Набор минимальных необходимых интерфейсов для хостов и модулей,
- SAL.Windows — Зависит от SAL.Core. Набор интерфейсов для хостов и модулей, поддерживающих стандартный функционал WinForms, WPF (Form, MenuBar, StatusBar, ToolBar…) приложений,
- SAL.Web — Зависит от SAL.Core. Набор интерфейсов для хоста и модулей, поддерживающих приложения, написанные с использованием ASP.NET (Нуждается в кардинальной доработке).
- SAL.EnvDTE — Зависит от SAL.Windows. Предоставляет расширения для плагинов, которые могут взаимодействовать с оболочкой, на которой написана Visual Studio.
Для минимального функционирования системы, достаточно добавить ссылку на SAL.Core, а при необходимости реализовать или использовать расширения, добавить ссылку на соответствующий набор расширений интерфейсов. Либо самостоятельно расширить минимальный набор интерфейсов нужной абстракцией.
Во время запуска хоста, первым делом инициализируются встроенные в хост базовые модули, для загрузки настроек и внешних плагинов (LoaderProvider и SettingsProvider).
Сначала инициализируется провайдер плагинов, а затем провайдер настроек. Встроенный в хост загрузчик ищет все плагины в папке приложения и подписывается на событие поиска зависимых сборок. Затем, встроенный в хост провайдер настроек, подгружает настройки из XML файла, находящегося в профиле пользователя. Оба провайдера поддерживают иерархическую инфраструктуру наследования и при обнаружении очередного провайдера становятся родителями нового провайдера. Если провайдер не находит требуемые ресурсы, то запрос ресурсов адресуется родительскому провайдеру.
После завершения процесса инициализации всех провайдеров, происходит инициализация всех Kernel, а затем и оставшихся плагинов. В отличие от остальных модулей, Kernel плагины инициализируются в первую очередь, получая возможность подписаться на события загрузки остальных плагинов с возможностью отмены загрузки лишних плагинов.
Данное поведение может быть переписано в хостах, если необходимо соблюсти иерархию загрузки других типов плагинов. Сейчас думаю о выносе последовательности загрузки модулей в Kernel.
Загрузка сборок
Стандартные LoaderProvider через рефлексию ищут все public классы, которые реализуют IPlugin и это не правильный подход. Дело в том, что если в коде идёт вызов конкретного класса или через рефлексию идёт обращение к конкретному классу, и этот класс не ссылается ни на какие сторонние сборки, то события AssemblyResolve не произойдёт. Т.е., сборку можно изъять из модульной инфраструктуры и использовать как обычную сборку добавив на неё ссылку и необходимость в SAL.dll отпадёт. Но базовые провайдеры модулей, реализованы по принципу сканирования текущей папки и всех объектов сборки, поэтому событие AssemblyResolve на все ссылающиеся сборки произойдёт на момент загрузки модуля.
Для решения этой проблемы, я написал несколько вариантов простых загрузчиков, но с разным поведением. В некоторых требуется указать список сборок заранее, некоторые сканируют папки самостоятельно.
В дальнейшем, как один из вариантов решения данной задачи, можно использовать сборку PEReader, которая описана ниже.
SAL.Core
Базовые интерфейсы и небольшие куски кода, реализуемые в абстрактных классах для упрощения разработки. В качестве самой минимальной версии фреймворка для основы, была выбрана версия .NET Framework v2.0. Выбор минимальной необходимой версии позволяет использовать базу на любых платформах поддерживающих эту версию фреймворка, а обратная совместимость (выбор рантайма при запуске) позволяет использовать основу до .NET Core (пока исключая).
В теории, базовые классы должны представлять из себя фундаментальную основу, позволяющие использовать их в любой ситуации. На практике же наверняка найдутся условия, для которых придётся их расширить. В этом случае весь код абстрактных классов можно переписать, а интерфейсы расширить собственной реализацией. Поэтому в этой сборке и находится самый минимум возможного кода.
На момент написания статьи единственным хостом, наследующим базовые интерфейсы, является хост для WinService приложений.
SAL.Wndows
Этот набор базовых классов, который предоставляет основу для написания приложений на основе WinForms и WPF. В составе идут интерфейсы для работы с абстрактным меню, тулбаром и окнами.
SAL.EnvDTE
С точки зрения расширения, хост как Add-In для Visual Studio расширяет интерфейсы SAL.Windows и дополняет специфичным для VS функционалом. Если зависимый плагин не находит ядра, взаимодействующего с Visual Studio, то он может продолжать работать с ограниченным функционалом.
Все написанные хосты, поддерживающие интерфейсы SAL.Core, автоматизируют следующий функционал:
- Загрузка плагинов из текущей папки,
- Сохранение и загрузка настроек плагинов из XML файлов в профиле пользователя,
- Восстановление позиций и размера всех ранее закрытых окон при открытии приложения (SAL.Windows).
На этих интерфейсах реализованы следующие хосты:
- Host MDI — Multiple Document Interface, написанный с использованием компонента DockPanel Suite,
- Host Dialog — Диалоговых интерфейс с контрольным управлением через Windows ToolBar,
- Host EnvDTE — Add-In для Visual Studio, проверенный на версиях EnvDTE: 8,9,10,12.
- Host Windows Service — Хост в качестве виндового сервиса, с возможностью установки, удаления и запуска через параметры командной строки (PowerShell не поддерживается).
Логирование событий реализовано через стандартный System.Diagnostics.Trace. В хостах MDI, Dialog и WinService, listener прописанный в app.config’е, пытается отдать полученные события обратно в само приложение через Singleton, которые затем отображаются в окнах логов (Output или EventList) в зависимости от события. Для devenv.exe тоже присутствует возможность прописать trace listener в app.config’е, но в данном случае мы получим загрузку сборки хоста до загрузки его в качестве Add-In’а. Поэтому trace listener добавляется программно в коде (Отображает в VS Output ToolBar или модальным окном).
Написанная инфраструктура позволяет развиваться в направлении HTTP приложений, но для этого необходимо реализовать часть модулей, обеспечивающих как минимум аутентификацию, авторизацию и кеширования. Для приложения TTManager, которое описано ниже, был реализован свой собственный хост для WEB сервисов, который реализовал в себе весь необходимый функционал, но, увы, он сделан под конкретную задачу, а не как универсальное приложение.
Такой подход логирования и разбивания на отдельные модули, позволяет с лёгкостью выявить узкие моменты при запуске в новом окружении. Для примера, при разворачивании массива модулей на Windows 10, обнаружил, что загрузка, занимает времени намного больше, чем на других версиях ОС. Даже на моей старенькой машине с WinXP, загрузка 35 модулей выполняется максимум за 5 сек. Но на Win10 процесс загрузки одного единственного модуля занимал куда больше времени.
Благодаря независимой архитектуре, локализовать проблемный модуль удалось мгновенно. (В данном случае проблема была в использовании рантайма v2.0 под Windows 10).
Готовые модули
Первая версия инфраструктуры появилась в 2009 году. Как для тестирования, так и для ускорения выполнения тривиальных задач по работе, накопилось большое количество разнообразных и независимых модулей, автоматизирующих разные задачи (Все картинки кликабельны, модули можно скачать на страницах проекта).
Web Service/Windows Communication Foundation Test Client
В основе этого приложения лежит приложение, идущее совместно с Visual Studio — WCF test client. На мой взгляд, в первоисточнике масса неудобных моментов. К моменту перехода на WCF у меня уже было написано много приложений на обычных WebService’ах. Изучив принципы работы самой программы через ILSpy, я решил расширить функциональность не только WCF, но и WS клиентов. В итоге, разобрав основную программу, я написал плагин со следующим расширенным функционалом:
- Поддержка WebService приложений (кроме Soap Header),
- Возможность тестирования сервиса со старыми binding’ами (при открытии не обновляет прокси-класс автоматом, а только по запросу из UI),
- Независимость от Visual Studio (объединил зависимые сборки через ILMerge),
- Вид всех добавленных сервисов в виде дерева, а не работа только с одним сервисом,
- Функция поиска по всем узлам дерева,
- На форму запроса сервиса добавлен таймер, чтобы отслеживать затраченное время на полное выполнение запроса,
- Добавлено восстановление отправленных параметров при закрытии и открытии формы теста или всего приложения,
- Добавлена возможность сохранения и загрузки параметров в файл по кнопке на форме теста метода.
- Добавлена возможность автосохранения и загрузки параметров метода (Понадобится модуль Plugin.Configuration → Auto save input values [False])
- Сломана возможность редактирования .config файла через программу SvcConfigEditor.exe
RDP Client
Опять же, первоисточником программы стали программисты из M$. В основе программы лежит программа RDCMan, но, в отличие от основной программы, я решил встроить окно подключённого сервера в диалоговый интерфейс. А удалённое хранилище настроек, помогло держать список серверов у всех причастных коллег в актуальном состоянии.
PE Info
В первоисточнике этого приложения лежит новая идея по автоматизации, которую я не смог найти в других приложениях. Цели написания такого приложения было 3:
- Предоставить интерфейс для просмотра содержимого PE файла, включая большинство директорий и таблиц метаданных (Хотя вывод ресурсов RT_DIALOG существенно отличается от оригинала).
- Поиск по структуре PE/CLI файлов
- Дать возможность загрузки PE файла не только из файловой системы, но и через WinAPI функцию LoadLibrary. В случае загрузки через LoadLibrary, есть шанс прочитать распакованный PE файл и не надо высчитывать RVA.
Несколько раз получалось, что исполняемые файлы реализовывали некий функционал, но этот функционал либо устаревал, либо никем не использовался. Чтобы не искать по исходным кодам приложений на разных языках использование тех или иных объектов и написано это приложение. Для примера, у меня есть сборка в общем репозитории и я решил удалить из этой сборки один метод. Как узнать, используется ли этот метод в текущих зависимых сборка других проектов написанными коллегами? Можно попросить проверить всех исходный код, можно посмотреть поискать в Source Control, а можно просто поискать одноимённый метод внутри скомпилированных сборок. Оно состоит из 2х компонентов:
- Сборка PEReader (написана без unsafe маркера), исходники которой доступны на GitHub’е,
- Клиентской части, которая представляет собой плагин для SAL инфраструктуры, используя уровень абстракции SAL.Windows.
Для поиска по иерархии PE, DEX, ELF и ByteCode файлов, был написан отдельный модуль, который замечательно вписался в инфраструктуру: ReflectionSearch. В данный модуль была вынесена вся логика поиска по объектам через рефлексию и благодаря нескольким публичным методам в модулях чтения исполняемых программ, удалось добиться многоразовости кода.
Остальные
Чтобы не описывать каждым отдельным пунктом весь список готовых модулей, я опишу оставшиеся модули одним списком:
- ELF Image Info — Разборка ELF файла по аналогии с PE Info. ElfReader на GitHub.
- ByteCode (.class) Info Разборка JVM .class файла. ByteCode Reader на GitHub
- DEX (Davlik) Info — Разборка DEX формата, который используется в Андройд приложениях. DexReader на GitHub
- Reflection Search — Сборка для поиска по объектам через рефлексию. Раньше была в составе модуля PE Info, но с появлением других модулей, была перенесена в отдельный модуль, используя публичные методы PE, ELF, DEX и ByteCode модулей.
- .NET Compiler — Компилятор .NET кода в реальном времени в текущем AppDomain. Предоставляет возможность написания кода (TextBox), хостинга скомпилированного приложения, кеширования скомпилированного кода и хранения скомпилированного кода как в виде отдельной сборки (Используется во второй итерации автоматизации приложения HTTP Harvester [Описан ниже]).
- Browser — Хостинг для Trident’а с расширенным функционалом получения XPath (самописный, на подобии HtmlAgilityPack) к DOM элементам. (Используется на третьей итерации автоматизации приложения HTTP Harvester [Описан ниже]).
- Configuration — Пользовательский интерфейс для редактирования настроек плагинов, ибо не все настройки доступны через UI при использовании SAL.Windows.
- Members — Отображение в UI public элементов плагинов, которые доступны для вызова извне.
- DeviceInfo — Сборка, способная прочитать S.M.A.R.T. атрибуты с совместимых устройств и работает без unsafe маркера. Для получения всех данных используется WinAPI функция DeviceIOControl, исходный код самой сборки доступен на GitHub’е.
- Single Instance — Ограничение приложения единственным экземпляром (Обмен ключами осуществляется через .NET Remoting),
- SQL Settings Provider — Провайдер сохранения и загрузки настроек из MSSQL. (код писался на ADO.NET и хранимых процедурах с размахом на унификацию, поэтому для отдельных СУБД придётся писать свои реализации хранимок),
- SQL Assembly scripter — Создание Microsoft SQL Server скрипта из .NET сборки для установки управляемого кода в MSSQL (не проверен на unsafe сборках),
- Winlogon — Модуль предоставляет публичные события для SENS интерфейсов. Первая версия использовала Winlogon, но он больше не поддерживается.
- EnvDTE.PublishCmd — Этот модуль я детально описал тут.
- EnvDTE.PublishSql — Перед или после ручной публикации выполненяет произвольный SQL запрос через ADO.NET с указанием шаблонных значений.
Остальные тут (Всего выложено около 30 модулей). Изображения всех модулей тут.
Готовые решения
Для наглядной демонстрации удобств построения всего комплекса на модульной архитектуре, я приведу пару готовых решений построенных на разных принципах:
- Полная независимость модулей между собой
- Частичная зависимость от Kernel модуля
TTManager
Приложение для системы задач, которое в основе использовало систему динамического расширения с возможностью использования разных источников задач. В итоге получился унифицированный интерфейс, который способен создавать, экспортировать/импортировать, просматривать задачи из разных источников. На текущий момент поддерживает в качестве источника MSSQL, WebService и частично REST API задач Мегаплана (не реклама). WebService написан по аналогичному принципу, с использованием базовых классов SAL.Web. Так что сам WebService также могут использовать в качестве источника MSSQL, Мегаплан или опять WebService.
Как работает
Kernel плагин приложения, ленивой загрузкой ищет все плагины источников задач (DAL). Если найдено несколько плагинов доступа к данным, то клиенту предлагается выбрать тот плагин, который он хочет использовать (Только в SAL.Windows, в хостах без пользовательского интерфейса — вылетит с ошибкой). Зависимые плагины получают доступ к выбранному DAL плагину через Kernel модуль.
Интересные моменты
В данном примере Kernel плагин абстрагирован интерфейсами от остальных зависимых плагинов. В таком случае, можно написать ещё один Kernel модуль (или переписать текущий). Или переписать вообще любой плагин) для возможности работать с несколькими источниками задач одновременно.
Для решения проблемы со статусами задач, внутри некоторых DAL плагинов зашита матрица статусов (Или берутся из источника задач, если есть). В таком случае не возникает проблем с переносом данных из одного источника в другой.
HTTP Harvester
Приложение позволяет, используя готовые плагины, парсить сайты через Trident или WebRequest. Для парсинга доступно несколько уровней абстракции. Самый низкий уровень позволяет написать дополнительный плагин, который будет заниматься открытием и парсингом ответа, используя DOM или ответ от сервера. Уровень выше предлагает написать .NET код в рантайме, который через плагин “.NET Compiler” будет скомпилирован и применён к результату страницы, отображаемой в Trident’е в рантайме. Самый высокий уровень предполагает указание, через UI, элементов на странице сайта отображаемой в Trident’e. И после применения xpath (самописный вариант) шаблона, передать на обработку в универсальный плагин или выполнить .NET код из плагина “.NET Compiler”.
Как работает
Модулю, зависимому от Kernel плагина, предлагается выбрать один из готовых интерфейсов вывода и базовый пользовательский интерфейс скачивания данных. Либо Trident, либо WebRequest с возможностью логирования. Kernel предлагает не только интерфейс, но и таймер опрашивания каждого отдельного модуля.
Интерфейс вывода предлагает стандартный GridView с контейнером вывода данных, с возможностью сохранения последней открытой позиции в таблице. По умолчанию контейнер поддерживает отображение изображения или текстовых данных.
Интересные моменты
В данном случае я не стал абстрагироваться от Kernel плагина интерфейсами и все зависимые плагины ожидают найти в массиве подгруженных плагинов конкретный Kernel плагин.
Приложение писалось в 3 итерации (Только под SAL.Windows):
- Сделана возможность написать плагин используя базовые элементы управления и массив методов работы с Trident описанные в Kernel плагине
- Появилась возможность заменять код в плагина используя рантайм код генерируемый и редактируемый в Plugin.Compiler
- Появилась возможность указывать в Trient путь к узлам HTML через UI. В результате для рантайм или онлайн кода отдаётся массив Ключ/Значение, где значением является путь к HTML элементу(ам) на подобии реализации в HtmlAgilityPack)
Что уже устарело и удалено
- Удалён Host для Office 2010. Он был написан исключительно для возможности создавать из контекстного меню задачу для TTManager, но из-за обилия костылей и ограниченности возможностей, дальнейшая поддержка оказалась нецелесообразной.
- Удалена возможность создания окон в EnvDTE через ATL. До VS 2007 возможность создания окон в студии была реализована только через ATL и COM. Затем появилась возможность всё делать через .NET.
- Устарел хост для EnvDTE реализованный как Add-In
Известные ошибки
Хост EnvDTE проверен только на английских студиях. Могут возникнуть проблемы на локализованных версиях (Один раз испытал на VS11 с русской локализацией).
Хост EnvDTE закрывает студию, если подгружен плагин Winlogon (SENS) и пользователь решил выгрузить хост через Add-in Manager. (Встретил на Windows 10).
Т.к. Хост написан как Add-In, а не как полноценное расширение, то совместимости с другими продуктами на основе EnvDTE — нет.
Какие прогнозы дальнейшего развития
При желании использовать функции кеширования, в довесок к встроенным классам System.Web.Caching.Cache и System.Runtime.Caching.MemoryCache, доступны удалённые кеши. Для примера, AppFabric. Написав базовый интерфейс клиента для кеширования, можно разработать массив модулей для каждого вида кеша и выбирать нужный модуль по необходимости (На момент публикации уже написаны, но не выложены).
Модули на момент написания могут подгружаться с файловой системы, с файловой системы в память и обновляться по сети, используя в качестве TOC XML файл. Дальнейшее развитие позволяет использовать в качестве хранилища не только с файловой системы, но и использовать nuget как хранилище или реализовать хост, который позволяет запускать модули удалённо.
Персонализация пользователя возможна как Roles, так и Claims. Но при использовании OpenId, OAuth, OpenId Connect, провайдеров существует огромное множество, при этом от каждого провайдера требуется получить System.Security.Principal.IIdentity (При использовании Roles based auth) или System.Security.Claims.ClaimsIdentity (При использовании Claims аутентификации). Соответственно, один раз написав клиента для LinedIn’а, можно его использовать в любом приложении без перекомпиляции.
При использовании очередей сообщений можно написать модуль и набор интерфейсов, который будет выполнять функции ServiceBus, а модули реализации конкретной очереди уже будут отвечать за получение и отправку сообщений.
Можно написать UI интерфейс динамического связывания публичных методов модулей, по аналогии с SSIS или BizTalk сервисами.
Переход на модульную архитектуру в iOS-проекте: опыт Redmadrobot
В Redmadrobot мы всегда стараемся выстраивать долгосрочные отношения с клиентами. Например, одно приложение для банковского клиента мы делаем с 2014 года. За 6 лет много чего поменялось в этом проекте. Мы не только полностью меняли дизайн, развивали функциональность, но и регулярно проводили рефакторинг кода.
За первые 5 лет на проекте архитектура менялась несколько раз, чтобы соответствовать последним стандартам в отрасли и последним обновлениям SDK. Тем не менее размер команды за эти годы рос не так активно, как функциональность приложения. В какой-то момент текущим составом мы стали не успевать делать все новые задачи, все чаще было сложно проследить зависимости внутри проекта, «не толкаться локтями» с другими разработчиками при параллельной разработке фич. Время на слияние изменений росло за счет большего количества конфликтов, время сборки проекта также росло за счет объема кода и не сделанных вовремя оптимизаций.
Одно из последних в отрасли решений для оптимизации больших мобильных приложений — разделение проекта на внутренние модули. Мы были далеко не первыми, но те, кто уже это пробовал этот подход в других крупных компаниях, отзывались крайне положительно.
В этой статье я поделюсь опытом и советами по переходу на модульную архитектуру.
Какие задачи ставили
1. Максимальное переиспользование кода
Количество команд и разработчиков планировалось увеличить в 5 раз до конца года. Также нужно было, чтобы каждая команда могла отвечать за конкретный модуль и были видны границы этой ответственности, было понятно, какими готовыми решениями можно пользоваться при разработке, а не писать похожие в каждой отдельной команде. И разработка внутри модуля должна минимально влиять на остальные части проекта.
2. Поддержка слабой связности между модулями
Когда разработка ведется в рамках одного проекта без разделения на модули, легко нарушать принцип инверсии зависимостей – с модулями это сделать намного сложнее.
3. Возможное переиспользование модуля в других приложениях
Изначально эта задача была неявной, но, очевидно, что модуль UI-компонентов или модуль чата можно переиспользовать повторно в других приложениях клиента. То же самое можно делать и с расширениями.
Например, помимо основного iOS-приложения, у нас есть расширения для iMessage, Siri и уведомлений. Не так много кода дублировалось, но мы решили свести его «копирование» в разных частях приложения к нулю.
4. Уменьшение времени сборки
Сборка «на холодную» (с пустым кэшем) на старте составляет около трёх минут на свежем Macbook Pro. А вот компиляция «на горячую» (из кэша) составила полторы минуты. Чем быстрее, тем лучше – почему бы не попробовать сделать в том числе и это.
5. Отследить, насколько может увеличиться или уменьшиться время запуска приложения
Если разделение на модули выполнено через динамические фреймворки, то неизбежно растет время запуска. Важно, чтобы это время оставалось в разумных пределах и в случае чего можно было отследить «проблемные» модули.
Всегда интересно решать новые задачи, а в данном случае нужно было всё переосмыслить в широком смысле. Так как в нашей компании нет отдельного архитектора под такие задачи, эту роль берут на себя разработчики.
На старте работ по переходу на модульную архитектуру было так: 4 iOS-разработчика, монолитная архитектура, нужно переписать приложение, созданное 5 лет назад, 300 000 строк кода, 85% из которых — Swift.
Когда мы говорим слово «модуль», под ним можно подразумевать самые разные вещи: зависимости в Cocoapods, таргет динамического фреймворка, подпроект с динамическим фреймворком в качестве таргета. Давайте рассмотрим каждый из них далее.
Разделение на модули
Мы давно используем Cocoapods в качестве менеджера зависимостей. Это наиболее популярный инструмент для подключения зависимостей к Xcode-проектам. Как мы делим? Монолитную модель на вертикальные слои — модель, сервисный уровень, общий пользовательский интерфейс, а также горизонтальные слои-функции. Самое крутое, в модулях то, что благодаря им можно устанавливать прямую зависимость с конкретным модулем, а не со всем приложением.
Но если не подумать о том, как делить, а просто начать «делать», то результат работы будет как на картинке ниже.
Первым делом мы попытались выделить нижележащий модуль — модуль сервисов (объекты, которые делают запросы в сеть или базу данных). Он зависит от библиотеки сетевых запросов Alamofire, а также от моделей (объекты приложения). Но модели теперь являются частью основного монолитного приложения. Появляется циклическая зависимость между модулем и основным еще пока «монолитным» приложением, что недопустимо.
Я рекомендую начать с простых вещей, таких как стили (шрифты, цвета), других библиотек, которые у вас есть. Например, папка с исходным кодом в вашем приложении (загрузчики, логгеры, аналитика). После этого переходим на слой моделей и извлекаем модели. Мы используем разные модули для моделей (структур) и DTO (Декодируемые объекты).
Далее мы извлекаем код, который имеет дело с базой данных, общими элементами пользовательского интерфейса и функциональными модулями.
Различные способы деления на модули
Cocoapods
Наш простой podfile.
platform :iOS, ’13.0’
use_frameworks!
target ‘ModuleExample’ do
pod ‘Model’, :path => ‘Model’
end
```
Podspec for Model module.
Pod::Spec.new do |s|
s.name = ‘Model’
s.version = ‘1.0’
s.summary = ‘Model Module’
s.homepage = ‘a link’
s.author = { ‘vani2’ => ‘[email protected]’ }
s.source = { :git => ‘a link’, :tag => s.version, :submodules => true }
s.platform = :iOS, ’13.0’
s.swift_version = ‘5.1’
s.source_files = ‘Classes/*’
end
```В Навигаторе теперь выглядит всё так:
User.swift
```swift
public struct User {
public let name: String
public init(name: String) {
self.name = name
}
}
```swift
import UIKit
import Model
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate { let user = User(name: “Johny”)
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
return true
}
}
```Зачем вообще использовать Cocoapods:
- Для повторного использования в других проектах. Cocoapods позволит сделать отдельный фреймворк и положить его в приватный репозиторий. Дальше использовать Cocoapods довольно просто, надо всего лишь правильно установить имя pod и правильное хранилище спецификаций или ссылку на приватный git.
- Cocoapods делает всё сам. Например, логины и импорты. И заодно он правильно интегрирует фреймворк в рабочее пространство. Но это не отменит необходимости отключать подпись подпроекта сертификатом разработчика.
Динамический фреймворк
Добавляем новый таргет и выбираем правильный шаблон.
Также нужно добавить фреймворк к главному подпроекту. Заодно провести проверку принадлежности файла (file membership) при добавлении его же в новый модуль.
Теперь наш pod выглядит примерно так:
platform :iOS, ’13.0’ use_frameworks! target ‘ModuleExample’ do end target ‘Service’ do pod ‘Model’, :path => ‘Model’ end ``` Service.swift
import Foundation
import Model
public class Service {
public init() {}
public func getUsers() -> [User] {
return [User(name: “Johny”)]
}
}
```Использовать можно вот так:
```swift
import UIKit
import Service
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
let user = Service().getUsers()
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
return true
}
}
```Подпроект
Создаём новый проект с динамическим фреймворком и добавляем в наше рабочее пространство.
Результат будет следующим.
```swift
import UIKit
import Service
import Database
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
let user = Service().getUsers()
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
Database.clean()
return true
}
}
```
Также нужно добавить Database.framework в зависимость от main target в качестве модуля Service, который был до этого. Таким образом, вы создадите проект с таргетом динамического фреймворка и добавите его в качестве зависимости. Что это даст:
- Принадлежность файла теперь управляется автоматически — файл может принадлежать только одному проекту.
- pbxproj-файл не раздувается до огромных размеров.
В своей работе мы используем утилиту XcodeGen. В ней объединение в pbxproj-файл делается не так сложно. До этого момента ключевая сложность заключалась в том, что подпись нужно было отключать скриптом.
Теперь Appdelegate выглядит вот так:
```swift
import UIKit
import Service
import Database
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate
let user = Service().getUsers()
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool
Database.clean()
return true
}
}
```На данный момент Swift Package Manager не поддерживает использование ресурсов (изображения, шрифты, текстовые файлы и т.п.). Как альтернатива – Carthage, который мы не использовали, а управление сабмодулями в git — ещё менее удобно.
Мы выбрали способ деления на модули через подпроекты – по большей части исходя из того, что он самый простой и быстрый для старта и пока нам не нужно использовать модули в других приложениях. Если такие модули появится, то для этого мы сделаем cocoapods-модули. Данные способы вполне сочетаются друг с другом, поэтому их можно комбинировать.
Итоговый вид архитектуры
Граф зависимостей стал гораздо понятнее. Когда будете извлекать модули, то можно попасть на циклическую зависимость. И это вполне решаемая проблема. В Siri Extension будут работать сервисы и модели. Получается, что мы делим целое приложение на функции, которые должны использовать протоколы для связи между модулями. Не поленитесь и нарисуйте целевую схему модулей и зависимостей. Делайте это несколькими разработчиками, можно даже позвать кого-то из коллег с другого проекта для «свежего» взгляда.
Но не всё так просто
- Чтобы добавить новые функции в приложение и рефакторинг для модулей, нужно быть джедаем в Git Merge.
- Каждый класс, свойство, функция, выходящие наружу, должны быть публичными для модуля и быть в доступе. И, если у вас есть структуры, нужно писать инициализатор для каждой публичной структуры (Swift создаёт внутренний инициализатор).
- Нужно будет помучиться со статическими библиотеками, вроде Google Maps. А классы будут дублироваться, если добавлять их по два и более раза. Это замедлит запуск приложения.
- Если раскадровки и nib-файлы содержат пользовательские классы для элементов управления, то нужно каждый раз проверять имя модуля после извлечения нового модуля с классами пользовательского интерфейса.
Оптимизация времени сборки
Для удобного просмотра времени сборки можно включить его отображение через команду в терминале:
$ defaults write com.apple.dt.Xcode ShowBuildOperationDuration -bool YES
После успешной сборки, оно отобразится в поле статуса, либо время сборки можно найти в логах сборки (панели слева).
Вот несколько достаточно распространенных советов, как уменьшить время сборки проекта, которые нам также оказались полезными (все они есть на вкладке Build Settings, можно найти их поиском):
- Отключение Whole Module Optimization (SWIFT_WHOLE_MODULE_OPTIMIZATION = NO) для отладочного режима. Для релиза оставляем настройку включенной.
- Удаление dSYM файлов для отладки. (DEBUG_INFORMATION_FORMAT = dwarf). dSYM-файлы генерируются при каждой сборке проекта, они нужны, например, для поиска куска кода, когда приложение экстренно завершает работу (крашится) в продакшене.
- Включение инкрементального режима сборки для отладки (SWIFT_COMPILATION_MODE = singlefile). С помощью этой настройки при новой компиляции перекомпилируется только измененный код.
- Включите многопотоковую сборку. С этой настройкой проект компилируется в несколько потоков.
- Проверьте, не включена ли старая система сборки в настройках Workspace.
- -Xfrontend -warn-long-function-bodies=300 and -Xfrontend -warn-long-expression-type-checking=300. На этих настройках вы получите предупреждение для функций и выражений с длинным временем компиляции (300 ms). Затем можно заняться оптимизацией конкретных выражений, и в итоге время компиляции будет меньше принятой границы. Советую подобрать величину границы самостоятельно, исходя из количества полученных предупреждений и времени, которое у вас есть на переписывание проблемных частей кода.
- Сборка при отладке проекта только для той архитектуры устройства, которая выбрана (ONLY_ACTIVE_ARCH = YES).
- Optimization Level (SWIFT_OPTIMIZATION_LEVEL = “-Onone”) — не оптимизировать отладку. Этим мы сокращаем итоговое время на величину времени оптимизации.
Итого
На первой итерации рефакторинга мы выделили 10 модулей. Время запуска приложения выросло всего на 50 мс, итого стало равным 800 мс. В этом направлении еще точно стоит поработать. Самое очевидное решение – выделение модулей в статические фреймворки. Недостаток состоит в том, что у статической библиотеки может дублироваться код. Это если есть общая зависимость с другим модулем, а также от системных библиотек. Следствие этого – больший размер приложения.
Рефакторинг сложных языковых конструкций, которые долго компилируются, выявление и исправление связей между классами в модулях и оптимизация настроек сборки дала прирост горячей сборки в шесть раз, с 1:30 до 0:23 секунд (при минимальном изменении и наличии кэша от предыдущей компиляции). Но в противовес этому холодная сборка (с чистым кэшем) выросла на 60% и теперь составляет 6 минут. В повседневной работе на порядок чаще разработчики имеют дело именно с «горячей» сборкой, а «холодная» сборка более актуальна при компиляции релизов для тестирования или публикации.
В дальнейшем стоит задача по выделению горизонтальных модулей – модулей для различных сценариев приложения.
Автор: Иван Вавилов, руководитель iOS-разработки Redmadrobot
Если вы нашли опечатку – выделите ее и нажмите Ctrl + Enter! Для связи с нами вы можете использовать [email protected].Проблемы и особенности разработки модульных приложений на Java
OSGi
Что делать, когда стоит задача разработать по-настоящему модульную архитектуру на языке Java? На помощь приходит OSGi (Open Services Gateway Initiative) – спецификация динамической модульной системы и сервисной платформы для Java-приложений, разрабатываемая OSGi Alliance. Спецификация описывает такую модель разработки ПО, при которой компоненты обладают всеми тремя описанными выше признаками. Основой концепции OSGi являются 2 сущности: наборы (Bundles) и сервисы (Services).
Наборы OSGi
При разработке ПО на Java, как правило, используются сторонние библиотеки. В мире Java библиотеки упаковываются в специальные файлы с расширением JAR (Java ARchive). Это обычный ZIP-архив, в котором находятся Java-классы (файлы с расширением .class). При этом использование библиотек может быть сопряжено с определенными сложностями.
Как только вы начинаете использовать какую-либо библиотеку в своем приложении, вам, как правило, становятся доступны все классы в этой библиотеке. Дело в том, что разработчики библиотек не имеют возможности спрятать классы, которые используются для реализации их внутренней логики. Таким образом, если вы используете код, который не предполагался для применения вне библиотеки, вы можете столкнуться с несовместимостью при использовании новой версии библиотеки или нарушить ее корректное функционирование.
Еще одной проблемой является так называемый JAR Hell. Многие разработчики сломали об него немало копий. Суть состоит в том, что как только у вас в проекте начинают использоваться разные версии одной и той же библиотеки (как правило, это большие проекты, которые эволюционируют со временем), вы можете столкнуться с ситуацией, когда один и тот же класс имеет разные методы в разных версиях библиотеки. Java же устроена так, что будет использована первая версия библиотеки, которую найдет загрузчик классов. Тем самым, обратившись в коде к какому-либо классу во время выполнения программы, вы получите ошибку, что метод, к которому вы обращаетесь, не существует. Связано это с тем, что на этапе выполнения Java ничего не знает о версии библиотеки, которая должна использоваться в том или ином случае.
Стоит отметить, что разработчики OSGi решили не изменять структуру JAR-файлов для обеспечения модульности, а просто добавили в них дополнительную информацию, которая используется средой OSGi. Более того, эта дополнительная информация никак не влияет на использование JAR-файлов в обычных Java-приложениях. Итак, чтобы JAR-файл стал OSGi-набором, в него добавляются данные, которые определяют, какие пакеты данного набора доступны для использования вне его (Export-Package) и какие пакеты других наборов требуются для работы этого набора (Import-Package). При этом возможно задать как версию API, которую набор предоставляет для других наборов, так и версию или диапазон версий API, которые набор требует для своей работы от них же. Все классы набора, которые не находятся в его экспортируемой секции, не доступны вне набора (Private). Таким способом OSGi-набор выполняет требование слабой связности.
Сейчас большинство Java-библиотек уже являются OSGi ready, т.е. содержат информацию для возможности выполнения в OSGi-контейнере. Также существует множество инструментов и утилит, которые позволяют создать из обычных JAR-файлов модули для OSGi.
Рис. 1. Импорт/экспорт пакетов в OSGi-наборах
Так как зависимости между наборами и интерфейсы, предоставляемые этими наборами, имеют четкие версии, среда выполнения OSGi позволяет легко избегать ситуаций JAR Hell, которые мы описали выше.
Таким образом, немного расширив описание обычного JAR-файла и добавив поддержку этого описания в среду выполнения, OSGi-сообщество решило проблему создания модулей в Java. Среда выполнения OSGi позволяет динамически загружать и выгружать новые наборы во время выполнения. Более того, OSGi отслеживает зависимости между наборами и динамически разрешает их.
Сервисы OSGi
Итак, имея OSGi-наборы, мы можем разрабатывать модульные приложения, которые взаимодействуют посредством интерфейсов (API). Возникает вопрос: где взять класс, который реализует требуемый интерфейс? Добавить такой класс в API набора – плохое решение, т.к. в рамках модульной архитектуры мы договорились не использовать внутренние классы наборов вне этих наборов. Можно было бы использовать шаблон «фабрика» для реализации интерфейса и добавить его в API набора, но разрабатывать каждый раз новый класс для сокрытия реализации интерфейса тоже кажется не лучшей идеей.
OSGi решает задачу поиска реализации интерфейса посредством реестра сервисов. Набор может зарегистрировать реализацию с описывающим ее интерфейсом в реестре сервисов. Набор, который использует интерфейс из другого набора, может выполнить поиск в реестре требуемой реализации нужного ему интерфейса. Как правило, наборы регистрируют сервисы при запуске в OSGi-контейнере. Более того, в реестре сервисов могут быть зарегистрированы одни и те же интерфейсы с разными реализациями и дополнительными идентификационными данными. При этом набор, который ищет в реестре требуемый ему сервис, может выбрать наиболее подходящий (например, используя фильтрацию).
Рис. 2. Публикация OSGi-сервиса в реестр сервисов. Получение опубликованного OSGI-сервиса из реестра сервисов
Микросервисная архитектура в виртуальной машине Java
Некоторое время назад микросервисная архитектура наделала много шума в ИТ-сообществе. Особенно бурно ее стали обсуждать после того, как признанный гуру Мартин Фаулер в соавторстве с Джеймсом Льюисом опубликовал статью «Microservices», в которой подробно рассмотрел преимущества разбиения монолитной архитектуры на набор независимых модулей. Каждый из таких модулей представляет собой отдельное приложение. Каждое приложение разрабатывается и развертывается независимо от других. Взаимодействие же между модулями происходит посредством четко определенных интерфейсов с использованием легковесных протоколов (REST, Protocol Buffers, MQ и т.д.). По факту каждый модуль – это микросервис, который выполняет одну определенную задачу и, как правило, содержит минимальное количество кода. Преимуществами такого подхода к разработке ПО являются:
- Легкость (при разработке микросервиса выполняется реализация всего лишь одной конкретной части функциональности. При этом нет нужды беспокоиться о других частях программы).
- Простота замены (если вы решите, что в текущей реализации сервис не справляется со своей задачей, вы легко можете переписать его и заменить на новую версию без какого-либо влияния на другие части программы. Более того, без остановки текущего ПО).
- Повторное использование (т.к. микросервис выполняет одну маленькую задачу, он может многократно использоваться там, где это необходимо).
Как видно из описания выше, разработчики модульных приложений с применением OSGi давно пользуются всеми преимуществами микросервисной архитектуры, но только в рамках виртуальной машины Java. Каждый набор с OSGi, который публикует сервис в реестр, является микросервисом внутри Java Virtual Machine, JVM (в мире OSGi такие микросервисы называются µServices).
Red Hat JBoss Fuse
Мы в Центре программных решений используем все преимущества OSGi при разработке ПО для телеком-операторов, страховых, процессинговых компаний. Для этого мы применяем продукт Red Hat JBoss Fuse, а конкретно его конфигурацию Fuse Fabric. Платформа JBoss Fuse предоставляет гибкую OSGi-среду для выполнения модульного приложения.
Сегодня к ПО предъявляются такие требования, как непрерывность работы, возможность легкого горизонтального масштабирования, простота развертывания и наличие средств управления кластером для кластерного ПО. Fuse Fabric решает эти задачи. Технология позволяет развернуть несколько экземпляров Red Hat JBoss Fuse и объединить их в кластер, а также предоставляет централизованный инструмент управления получившейся средой.
В рамках Fuse Fabric существуют следующие абстракции:
- Фичи (features) – совокупность OSGi-наборов, которые реализуют какой-либо функционал.
- Профили (profiles) – совокупность фич, которые должны выполняться в рамках одного контейнера, и конфигурационные настройки для наборов, которые входят в фичу.
- Контейнеры (containers) – отдельные JVM-процессы, которые выполняются на конкретном узле кластера Fuse Fabric под управлением контейнера Red Hat JBoss Fuse.
Рис. 3. Иерархия сущностей в Fuse Fabric
Таким образом, любое ПО, которое строится на технологии Fuse Fabric, состоит из OSGi-наборов, которые группируются в фичи и развертываются в рамках какого-либо отдельного JVM-процесса на одном или нескольких узлах кластера в соответствии с заранее заданным профилем.
Среда Fuse Fabric содержит множество инструментов, которые позволяют легко управлять полученным кластером. Мы можем создавать профили, на основе профилей создавать контейнеры, создавать/удалять/запускать/останавливать контейнеры на любом хосте, который входит в кластер, подключать новые узлы кластера и т.д. И все эти действия мы можем выполнять online, т.е. без прерывания функционирования остальных узлов кластера. Среда поддерживает возможность хранения нескольких версий профилей, фич, OSGi-наборов.
В полученной среде OSGi-наборы могут взаимодействовать не только в рамках одного контейнера, но и вызывать друг друга в рамках разных контейнеров (даже в рамках различных хостов). Эту возможность обеспечивает технология Distributed OSGi. Дополнительно – при минимальных затратах на разработку – каждый сервис, который предоставляет OSGi-набор, можно превратить в REST/web-сервис, который можно вызывать из внешних систем.
Таким образом, используя Fuse Fabric, мы можем создавать микросервисную архитектуру, которая поддерживает простоту настройки и развертывания, изолированное выполнение сервисов в рамках своих JVM-процессов (со своими специфичными настройками, например, разными настройками сборщика мусора), при этом сервисы взаимодействуют между собой по сети с использованием легковесного протокола.
Т.к. продукт Red Hat JBoss Fuse основан на Open Source стеке технологий Apache ServiceMix, в нашем распоряжении есть такие мощные технологии, как Apache ActiveMQ (реализация спецификации JMS), Apache Camel (реализация шаблонов проектирования корпоративных приложений), Apache CXF (библиотека для разработки REST/web-сервисов), Blueprint (предоставляет возможности внедрения зависимостей), Spring и т.д. Поскольку указанные технологии бесшовно интегрируются между собой в Red Hat JBoss Fuse, это значительно снижает время разработки требуемого функционала.
Linux-MP. Модульная программа «Архитектура и администрирование Linux»
Уровень сложности:
Длительность курса: 80 ак.ч.
График обучения: 20 дней по 4 ак. часа или 10 дней по 8 ак. часов
Программа состоит из 2 отдельных курсов-модулей.
Аннотация
Целью изучения модульной программы «Архитектура и администрирование Linux» является формирование у слушателей знаний и навыков в области архитектуры ОС Linux, а так же умений необходимых для активного администрирования операционных систем семейства Linux.
Знания и умения, полученные в результате обучения
По окончании курса слушатели смогут:
- производить базовые задачи, такие как установка и первоначальная настройка ОС Linux
- выполнять установку и удаление программных пакетов
- работать со средствами графического и консольного управления системой
- производить базовые задачи, такие как файловая навигация в командной оболочке, поиск и управление файлами
- создавать и настраивать учетные записи пользователей и групп
- управлять устройствами, драйверами, дисками, томами и файловыми системами
- управлять системными и пользовательскими процессами и службами
- настраивать базовые параметры безопасности операционной системы, включая управление доступом к объектам файловой системы и настройкой прав
- управлять основными сетевыми компонентами системы
- настраивать резервное копирование и восстановление данных
- управлять подсистемой планирования выполнения заданий
- управлять подсистемой журнализации событий и подсистемой печати
- отслеживать производительность операционной системы и производить мониторинг системы
- выявлять основные типовые проблемы ОС Linux и находить способы их устранения
- понимать предназначение ключевых бинарных и конфигурационных файлов согласно стандарта FHS
- работать с текстовыми редакторами, использовать конвейер и регулярные выражения и утилиты sed, grep и awk
- рограммировать на языке командного интерпретатора Bash
- управлять системами инициализации SystemV и systemd
- отслеживать и контролировать запуск и останов системы
- управлять репозиториями и программными пакетами
- управлять параметрами загрузки ядра
- осуществлять администрирование ядра операционной системы
- настраивать параметры сетевой безопасности операционной системы, включая управление подсистемами iptables и firewalld
- настраивать опции безопасности, такие как SELinux/AppArmor
- управлять сетевыми функциями системы, такими как разрешение имен, маршрутизация, сетевая аутентификация
- настраивать сетевые службы Squid и VPN на базе ОС Linux
- управлять компонентами серверной инфраструктуры, такими как SSH, NFS, SAMBA, LDAP, DHCP, BIND, PXE, iSCSI
- осуществлять расширенное управление дисковой и файловой подсистемами и настраивать списки контроля доступа и квоты
- внедрять технологии виртуализации и контейнеризации на базе ОС Linux
Преподаватели
- Норка Евгений Олегович
Курсы связанных направлений
| Даты занятий | Расписание занятий | ||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
13.09.2021 – 24.09.2021 |
|
||||||||||||||||||||||||||||||||||||||||||||
|
08.11.2021 – 19.11.2021 |
|
Курс ориентирован на слушателей, имеющих опыт работы в Windows, обладающих базовыми знаниями об архитектуре компьютера и периферийных устройствах, а также базовые знания сетевых технологий. Желательно иметь представление об архитектуре современных операционных систем, операционной системы UNIX в частности
Программа состоит из отдельных курсов-модулей
Выберите ссылку для того, чтобы посмотреть программу отдельного модуля.
-
Linux-LE. Основы архитектуры и администрирования Linux
Курс «LINUX-LE. Основы архитектуры и администрирования Linux» является базовым курсом по администрированию ОС Linux и соответствует программе «Linux Essentials» некоммерческой организации Linux Professional Institute (LPI). Курс проводится с использованием материалов электронного курса «NDG Linux Essentials» сетевой академии Cisco, а также с использованием авторских учебных пособий Высшей инженерной школы СПбПУ.
-
Linux-LF. Расширенное администрирование ОС Linux
Целью изучения дисциплины «Расширенное администрирование ОС Linux» является формирование у слушателей знаний и навыков, необходимых для активного администрирования операционных систем семейства Linux.
Модульный IoT Интернет вещей Архитектура (1)
Модульная модульная сетевая архитектура IOT обеспечивает быстрые и простые решения для интернет-приложений. Пусть различные цифровые технологии быстро интегрируются в различные места в промышленном секторе.
Основные особенности модульного-2 IoT
Включите сценарий приложений от датчика до облака
modular-2
Модульные терминальные устройства, доступ к большому количеству датчиков, исполняемых компонентов в платформу ModullioT на основе недороговой реализации Corex-M односпальной реализации, используя операционную систему Интернет-операционной системы ARM.
Модульные-2 достигают развязки прикладного программного обеспечения и физических устройств. Пользователи пользователя могут быстро разрабатывать приложения, когда им не нужно понимать чрезмерное оборудование в основном технологии.
modular Edge
Модульный край – это модульный краевой сервер, который может быть установлен в различных промышленных сценах, завершение сбора данных, контроля, хранения данных и анализа данных. Он основан на OS Linux, который использует контейнерные технологии и концепции микросервисов для реализации программного обеспечения для интернет-приложения.
В соответствии с потребностями промышленного применения модульная-2 край может быть развернута на недорогой платформе процессора ARM или также может быть развернута в более мощной компьютерной платформе Intel X86. Сделайте промышленные информационные системы более эластичными.
modular cloud
Модульное облако – это модульное расширение архитектуры программного обеспечения кромки к облаку. Реализуйте оригинальное облачное применение. Доступ к запуску сети доступа к бизнесу доступа к бизнесу или доступ к HTTP, MQTT, Websocket.
Приложение приложений программного обеспечения
Одной из основных особенностей архитектуры Modulario Architection реализует приложение в краевых устройствах и облачных приложениях, которые используют контейнерную технологию и философию микросерссы.
Контейнеры облачных приложений и концепции микросервисов имеют деконструкцию, простым в эксплуатации, языковых нейтральных, многоуровневых сосуществовании, быстрой итерации и развертывании и т. Д., Но это в основном архитектура больших облачных приложений, большое количество операций и обслуживания инструменты. Опытные операции должны быть использованы. Модульный IOT предоставляет полный набор программного обеспечения и норм, что делает операцию и развертывание контейнера и развертывание, а также опыт клиента близок к мобильному приложению. Включите персонал обслуживания в отрасли, чтобы легко завершить установку, развертывание и обслуживание приложения.
AppManager на модульном IO может реализовать пользовательский опыт, похожий на мобильное приложение. С этой целью Modulariot указывает сетевой протокол, систему сообщений, Webui и управления операциями приложения. Пользователи могут разрабатывать различные интернет-файлов приложений более удобных, и быстро развернуты на краевом устройстве или облако.
В то же время модульный IOT также постоянно развивает микросхемы для различных основных услуг, обеспечивая более мощную поддержку приложения приложения. Такие, как операторы (China Telecom Window и China Mobile OneNet) Доступ к сети, база данных временного ряда, цифровая панель, AI и другие услуги. Включите разработчики приложений, чтобы сосредоточиться на своих профессиональных полях, быстро разрабатывают различные приложения.
Нейтрализация языка развития
Вы можете использовать различные языки программирования для реализации приложения под модульной архитектурой IOT, которые могут быть C ++ или JavaScript на основе узла для Python для анализа данных. Мы рекомендуем использовать язык Go для разработки приложений ModullioT. Модульный IOT разработан, все программы реализуются в C ++, недавно мы обратимся от C ++, чтобы пойти. Приложение будет использоваться для использования Go для записи приложений более быстро и эффективно.
Основная технология, используемая модульным IoT
Управление контейнером докера
Приложение ModullioT и поддержка Micro-Service реализуют контейнер, и Docker в настоящее время является самым популярным технологиями управления контейнерами.
Система сообщения rabbitmq
Обмен сообщениями между модульным внутренним приложением IOT использует систему сообщений rabbitmq. Rabbitmq – это реализация с открытым исходным кодом AMQP, разработанная языком Erlang.
AMQP: Расширенная очередь сообщений, продвинутая протокол очереди сообщений. Он является открытым стандартом для протокола слоя приложений, предназначенного для ориентированного на сообщение промежуточное программное обеспечение, а клиентское и сообщенное промежуточное программное обеспечение на основе этого протокола могут быть переданы и не ограничены продуктом, язык разработки.
Перейти к языку программирования
Go – это новый язык программирования, разработанный Google, его стандартная библиотека поддерживает большое количество общих библиотек для сетевых протоколов и программирования. Используйте To To To Write Internet Applications очень эффективно и быстро. Мы рекомендуем написать программу приложения ModullioT с языком Go.
база данных
Модульный IOT использует две базы данных:
База данных MongoDB
Modulariot использует MongoDB для реализации управления приложениями.
База данных Time Series Time
protocol Buffer
Буферы протоколов – это легкий и эффективный структурированный формат хранения данных, который может использоваться для структурной серии данных или сериализации. По сравнению с XML и JSON обработка буфера протокола быстрее, а полученные данные последовательности короче. Это именно то, что требуется приложение IOT. В архитектуре ModullioT Mobingmq есть формат буфера протокола.
Модульная архитектура IOT
hub service
Все внешние устройства и услуги подключены к модульному IoT через службу HUB. Они включают модульные-2 устройства. Персонал, другие краевые устройства и другие услуги. Например, платформа доступа в Интернет отдел телекоммуникационного отдела.
Служба управления приложением
Управление приложением использует MongoDB для хранения и управления параметрами приложения.
Управление приложением
На платформе Moddullioio могут быть созданы несколько элементов, и каждый элемент может иметь несколько приложений. И есть несколько пользователей для использования этих приложений.
Например, на платформе IOT вы можете запускать проекты IOT компаний, и проект компании может одновременно определять три приложения с точки зрения контроля устройства, обнаружения состояния и здоровья оборудования. У этого приложения будут использовать несколько людей.
Создать проект
Запустите Интернет вещей проектов на модуляре, сначала создайте проект. Существует только один проект по модулярному краю, а несколько предметов можно запускать в облаке.
заявление
Может быть несколько приложений на каждом элементе (называемое «приложением» в этом документе).
администратор
У каждого проекта есть администратор (как «admin» в этом документе), он отвечает за создание, эксплуатацию и управление эксплуатацией приложения.
Пользователь
Есть несколько пользователей в каждом проекте, и у них есть администраторы проекта.
управление
В Modulariot приложение представляет собой контейнер Docker-Type. Когда приложение разработано, вам необходимо загрузить приложение Docker Image на частный репозиторий ModullioT (используя Docker Push). Также необходимо зарегистрироваться в Modulario Manager.
App Manager – это микроэлектрический сервис приложения и управления пользователя, который использует базу данных MongoDB для управления элементами, приложением и пользователем в системе.
зарегистрировано
Чтобы зарегистрироваться, предоставьте следующую информацию:
Имя название
-Browsername Браузер Имя
-Под этого приложения открытого порта
–Avatar Икона этого приложения
-ImageFile, Docker Имя изображения
Загрузите эту информацию через интерфейс управления программой Manager App Manager. После загрузки в App Manager он появится на странице управления программой App Manager, а состояние «Удалить»
монтаж
Установка приложения означает, что изображение приложения создано контейнер докера. После установки приложение автоматически входит в состояние запуска.
запустить
Приложение работает.
Стоп, приостановить
Приложение можно установить для остановки или приостановки, то контейнер приложения по-прежнему сохраняется в Docker, статус «Стоп»
отменить
Удалите контейнер приложения. Но изображение не удаляет из частного хранилища ModularioT, и информация о приложении по-прежнему сохраняется в App Manager. Приложение не установлено.
Удалить
Приложение полностью удалено на платформе ModullioT.
Последнее продолжение
Радченко Глеб Игоревич
Научные интересы
- Грид-вычисления.
- Облачные вычисления.
- Распределенные вычислительные системы.
Публикации
Проекты
- Проект Erasmus+ PWs@PhD. Основная цель проекта PWs@PhD – поддержка развития, модернизации, интернационализации высшего образования, а именно исследовательской составляющей европейского образования уровня PhD, содействие созданию новых PhD-программ в странах-партнерах в области программной инженерии.
- Сервисно-ориентированный подход к использованию проблемно-ориентированных пакетов в распределенных и грид-средах (проект DiVTB).
- Параллельная реализация нейросетевого алгоритма распознавания раздельной речи (Часть 1, Часть 2, Часть 3).
Новости
- [2013-12-25] Обновления страниц курсов:
- [2013-12-17] Обновления страниц курсов:
- [2013-11-28] Обновления страниц курсов:
- [2013-11-07] Размещены слайды презентаций:
- [2013-10-26] Размещены слайды презентаций:
- [2013-06-03] Размещены слайды презентаций:
[Архив новостей]
Ссылки
- Mendeley – система для каталогизации и управления библиографией. Встраивается в Microsoft Word, позволяя автоматизировать процесс управления списками литературы при подготовке статей. Поддерживает множество форматов оформления библиографических ссылок, включая ГОСТ-7.0.5-2008.
- Memsource – операционная среда для выполнения письменных переводов, включающая базы памяти переводов, встроенный машинный перевод, модуль управления терминологией, а также текстовый редактор MemSource Editor. Может импортировать и экспортировать документы всех стандартных форматов, включая Word и PowerPoint.
Мой профиль
Модульное программирование: определения, преимущества и прогнозы
Модульное программирование возникло еще в 1960-х годах, когда разработчики начали разбивать большие программы на более мелкие части. Хотя этой концепции около шести десятилетий, она по-прежнему чрезвычайно актуальна и полезна для современных разработчиков программного обеспечения и является одним из ключевых принципов программирования, которым мы следуем в Tiny.
Между прочим, этот блог является первым из серии о том, как мы используем принципы программирования в Tiny, так что следите за будущими статьями.
Начнем с некоторых определений.
Что такое модульное программирование?
Модульное программирование (также называемое модульной архитектурой) – это общая концепция программирования. Он включает в себя разделение функций программы на независимые части или строительные блоки, каждый из которых содержит все части, необходимые для выполнения одного аспекта функциональности. Вместе модули составляют исполняемую прикладную программу.
Примечание. Модули – это также концепция в JavaScript, которую вы можете использовать для реализации модульной архитектуры на одном уровне, хотя вы не ограничены реализацией модульной архитектуры в JavaScript.
В то время как большинство людей говорят о модульности на уровне файла / папки / репозитория, я думаю о модульности на нескольких уровнях:
- Функции внутри файлов
- Файлы в репозиториях / библиотеках
- Библиотеки / репозитории в рамках проектов
Модульность – это создание строительных блоков, и даже строительных блоков, состоящих из более мелких строительных блоков. Каждый из них является отдельным, надежным и тестируемым, и в конце его можно сложить вместе для создания вашего приложения.Такой подход к модульности также означает, что вы можете встроить ее в свой стиль кода и архитектуру. Вы можете создавать правила и рекомендации относительно того, что означает модульность на каждом уровне и как вы обрабатываете определенные вещи, например, как каждая часть определяется и расположена в файлах, папках и библиотеках.
Модули и API
Один очень полезный способ взаимодействия модулей – это интерфейсы или API. С помощью API вы раскрываете только те элементы, которые нужны разработчикам для использования модуля, при этом скрывая внутренности кода.
В некотором смысле это означает, что ваш API может действовать как контракт, определяя, что делает модуль / библиотека и как их можно использовать внешним кодом. Например, API может сказать: «В этом модуле есть функция, которая делает это и возвращает это».
С помощью API вы можете быть уверены в том, какие части модулей должны или не должны изменяться без предупреждения. Таким образом, даже когда вам нужно изменить или исправить что-то внутри библиотеки, другие вещи могут продолжать использовать API и быть уверены, что ничего неожиданно не изменится из-под них.Кроме того, гораздо проще взглянуть на модуль и узнать, для чего он может использоваться (я расскажу об этом чуть позже).
Модульное программирование в Tiny
В Tiny мы очень любим модульность. Например, монорепозиторий TinyMCE содержит несколько модулей, каждый из которых содержит код, относящийся к определенной функциональности. Например:
… и многие другие.
Каждый «модуль» затем содержит файлы и папки, которые соответствуют определенным правилам. Katamari – хороший пример с его папками API и Util, которые содержат определенные типы кода в соответствии с нашими стандартами и рекомендациями.Затем папка API содержит файл для каждой концепции, представленной через API Katamari, и все они собраны в файле Main.ts. Таким образом, если мы хотим узнать, какие методы у Katamari есть для массивов, мы можем просто взглянуть на Main.ts, чтобы увидеть, что предоставляет Katamari, и оттуда перейти к любому из файлов API, например Arr.ts, который содержит методы. для работы с массивами. Это позволяет быстро и легко найти код, который мы ищем.
В результате такой архитектуры сам TinyMCE состоит из большого дерева зависимостей библиотек вспомогательных функций (построенных на большем количестве библиотек вспомогательных функций!), Которые все собраны вместе в конце для создания редактора.Это может показаться сложным, но мы считаем, что преимущества того стоят.
Почему модульное программирование?
Цель модульного программирования – упростить разработку и сопровождение больших программ, разбивая их на более мелкие части. Он имеет ряд преимуществ:
Код легче читать
Модульное программирование обычно упрощает чтение кода, поскольку это означает разделение его на функции, каждая из которых имеет дело только с одним аспектом общей функциональности.Это может сделать ваши файлы намного меньше и более понятными по сравнению с монолитным кодом. Например, большинство наших файлов не содержат более пары сотен строк кода, тогда как я видел другие приложения, где в каждом файле были бы тысячи строк кода, что может затруднить отслеживание и чтобы найти конкретные предметы.
Модульное программирование может стать немного запутанным, если вы разделите вещи на слишком много мелких функций или если вы передаете данные или функции между слишком большим количеством файлов.Но если вы разумно разбили свои модули, это работает действительно хорошо – намного лучше, чем функция, состоящая из сотен строк!
На самом деле, я думаю, это одна из причин, по которой моя команда может избежать наказания за меньшее количество комментариев к нашему коду. Небольшая функция с хорошим описательным именем может помочь вам понять блок кода, не требуя комментариев к нему.
Код легче тестировать.
Программное обеспечение, разделенное на отдельные модули, также идеально подходит для тестирования. Это потому, что тесты могут быть намного более строгими и подробными, если вы тестируете небольшие функции, которые выполняют меньше функций, по сравнению с большими функциями, которые выполняют ряд функций.Это особенно верно, если вы можете тестировать только выходные данные функции, а не шаги, которые она выполняет.
Кроме того, более простое тестирование может означать, что потребуется меньше больших и подробных комментариев, поскольку тесты могут служить примерами того, как работает код. Если вы не понимаете блок кода, проверка тестов может быть простым способом получить хорошее представление о нем.
Легко найти вещи позже
Модульность включает в себя группировку функций схожих типов в их собственные файлы и библиотеки и разделение связанных вспомогательных функций в их собственные файлы (вместо того, чтобы оставлять их смешанными с кодом основной логики).Например, если вы зайдете на GitHub, вы увидите, что у TinyMCE есть определенные файлы, содержащие:
- Вспомогательные функции Unicode
- Вспомогательные методы работы с объектами
- Вспомогательные методы для массивов
… и этот список можно продолжить. Такое разделение функций может значительно ускорить и упростить поиск того, что вы ищете позже.
Благодаря модульному программированию вы можете упростить поиск определенного кода, создав соглашения для имен и местоположений файлов.Например, код для каждого плагина сообщества в TinyMCE следует определенной структуре папок, в которой группируются файлы, относящиеся к API, пользовательскому интерфейсу и основным функциям. Если вы можете догадаться, где может быть файл и как он может вызываться, будет намного проще искать и находить код.
Возможность повторного использования без раздувания
В большинстве случаев вам придется использовать один и тот же код или функцию в нескольких местах. Вместо того, чтобы копировать и вставлять код, модульность позволяет вам извлекать его из одного источника, вызывая его из любого модуля или библиотеки, в которой он находится.Например, наши библиотеки Katamari и Sugar используются в большинстве других наших проектов, поэтому удобно иметь возможность просто добавлять их как зависимости и иметь возможность обрабатывать структуры данных и манипуляции с DOM одинаково во всех наших проектах.
Это уменьшает раздувание и размер, поскольку у нас нет нескольких копий каждого бита кода, выполняющего определенную функцию.
Единый источник для более быстрых исправлений
Поскольку каждый модуль предоставляет единый источник достоверных данных для ваших конкретных функций, он сводит к минимуму количество мест, где могут возникнуть ошибки, и ускоряет их исправление, если они все же появляются.Это снижает риск проблем, вызванных тем, что два фрагмента кода полагаются на несколько разные реализации одной и той же функциональности. И если в коде есть ошибка или вам нужно обновить конкретную функцию, вам нужно исправить ее только в одном модуле, и все, что использует его, будет обновлено сразу. В то же время, если вы скопировали и вставили код в разные места, вы легко можете пропустить обновление одного или двух экземпляров.
Примечание: Иногда вам необходимо скопировать код по определенной причине.Когда мы делаем это, мы следуем правилам в отношении имени и местоположения кода, чтобы его было легко найти в будущем.
Более простые обновления с меньшим риском
При модульном программировании каждая библиотека имеет определенный уровень API, который защищает вещи, которые ее используют, от изменений внутри библиотеки. Пока вы не меняете API, гораздо меньше риск непреднамеренного взлома кода, который зависит от того, что вы изменили. Конечно, вам все равно нужно быть осторожным, но API определенно помогают прояснить ситуацию, когда вы собираетесь изменить публичную функцию.Например, если у вас не было явных API-интерфейсов, и кто-то изменил функцию, которая, по его мнению, использовалась только в той же самой библиотеке (но на самом деле она использовалась где-то еще), они могли случайно что-то сломать.
Более простой рефакторинг
Модульное программирование упрощает рефакторинг. Это связано с рядом причин, но, чтобы дать вам пример, оба API и следование строгой структуре файлов / папок могут помочь, если вы хотите создать сценарий или автоматизировать рефакторинг.
В конце 2017 года мы преобразовали TinyMCE в TypeScript.В рамках этого преобразования мы также реструктурировали TinyMCE, сделав его более модульным, разделив большую часть кода на плагины и библиотеки. Затем мы смогли использовать эту повышенную модульность и, в частности, структуру API, которую мы представили при автоматизации частей преобразования TypeScript. Это также помогло с ручной последующей работой, так как мы могли работать по разделам, плагин за плагином и библиотека за библиотекой. И годы спустя он по-прежнему помогает нам привлекать новых разработчиков, находить и исправлять ошибки, добавлять новые функции и многое другое.
Простота совместной работы
Модульное программирование необходимо, когда нескольким командам необходимо работать над различными компонентами программы. Когда несколько разработчиков работают над одним и тем же фрагментом кода, это обычно приводит к конфликтам Git и различным другим проблемам, которые могут раздражать и замедлять работу команды. Если код разделен между большим количеством функций, файлов и / или репозиториев, вы можете уменьшить вероятность того, что это произойдет.
Вы также можете назначить владение конкретными модулями кода, гарантируя, что команды несут ответственность за свою часть программного обеспечения, и позволяя им разбивать работу на более мелкие задачи.Команды (и модули) объединяются с четко определенными интерфейсами и общедоступными API, что гарантирует совместимость всего при развертывании.
Есть ли недостатки?
Должна быть причина, по которой некоторые люди не занимаются модульным программированием, верно? Ну да.
Альтернативой модульному программированию обычно является создание монолитного приложения кода, где весь ваш код (более или менее) сбрасывается в одно место. В результате может получиться «код спагетти», поскольку он скручен и запутан, как большая миска со спагетти 🍝
На самом деле есть несколько причин, по которым некоторые люди все еще пишут код спагетти:
- Размер кода – Модульность может увеличить размер кода и повлиять на производительность, если вы не можете встряхнуть свои зависимости.
- Сложность – Иногда сложные файловые системы не нужны и могут создавать ненужные накладные расходы
- Безопасность – Монолитный код может усложнить людям использование кода, который исходный разработчик не хочет изменять, взламывать или использовать пиратский
И давайте будем реальными – некоторым людям просто нравится жить на грани.Это как-то захватывающе, когда вы не уверены, что (в тысячах строк кода) сломано 😆
Если вы работаете над личным или небольшим проектом, размер и сложность которого невелики и их не так много людей, сотрудничающих с ним, вы также можете не получить такой большой пользы от модульного подхода.
Есть также множество старых проектов, которые существуют уже много лет, которые со временем могут превратиться в беспорядок, особенно если они пострадали от людей, добавляющих код в исходный проект, не понимая, как лучше всего его добавить.Такие проекты иногда даже достигают точки, когда им требуется структурная перестройка, поскольку ими становится слишком сложно управлять.
Итак, даже если ваш проект начинается с малого, подумайте, может ли модульный подход с самого начала помочь защитить ваш код в будущем. Конечно, если вы ожидаете, что ваш проект будет иметь долгую жизнь или стремительно расти, было бы хорошо с самого начала рассмотреть вопрос о модульности, потому что структурные перестройки могут быть очень сложными, требующими много времени и трудными для реализации, когда есть функции, которые нужно изменить. быть написанным.
Будущее модульного программирования
Модульное программирование – не новая концепция, но все еще очень популярна. Я считаю, что разработчикам важно знать, что это такое и почему это полезно. В конце концов, способ, которым ряд современных библиотек, фреймворков и менеджеров пакетов настроен для совместного использования кода и управления зависимостями, делает модульное программирование естественным выбором.
Например, существует множество библиотек NPM, которые выполняют только одну задачу. И все больше и больше разработчиков используют фреймворки, которые делают только определенные вещи, например Bulmer, фреймворк CSS, который довольно прост по сравнению с некоторыми другими популярными фреймворками CSS.Небольшие библиотеки могут показаться не такими впечатляющими из-за меньшей функциональности, но также требуется меньше обучения, прежде чем вы сможете их использовать, и они, как правило, меньше, поэтому меньше раздувания кода, чем в более крупных библиотеках.
Разработчикам важно понимать, что разработка программного обеспечения – это больше, чем просто написание кода, особенно в экосистеме Javascript. Речь идет о возможности находить, анализировать и использовать правильные строительные блоки, а также писать приложения, которые будут надежными и удобными в обслуживании.За всеми аспектами этого стоит модульность, и поэтому она так ценится.
Используйте TinyMCE с модулем связки
Вы уже реализуете принципы модульного программирования для своих проектов или хотите поиграть с концепцией?
Вы можете использовать TinyMCE в своем проекте с помощью загрузчика модулей, например Webpack или Browserify. Узнайте подробности о том, как это сделать, в нашей документации. У нас также есть специальная документация о том, как включить плагин PowerPaste с помощью загрузчика модулей.
Вы занимаетесь модульным программированием? Почему или почему нет?
Давайте продолжим разговор в Twitter @joinTiny – сообщите нам, используете ли вы или ваша команда модульное программирование и почему.И дайте нам знать, какой ваш любимый инструмент, который поможет вам сделать ваш код модульным!
Не забудьте подписаться на нашу рассылку, чтобы не пропустить остальные наши блоги из этой серии!
Модульная архитектура программного обеспечения – Tutisani Consulting
Выражайте сложные зависимости между классами и компонентами на одном уровне и легко управляйте ими, группируя их в модули.
Проблема
Самая популярная и распространенная трехуровневая программная архитектура была создана из-за необходимости краткости и пояснения графиков зависимостей между классами и компонентами.Если бы мы сохранили только один слой для всего приложения, эти графики были бы неуправляемыми и запутанными. Было бы невозможно определить какие-либо правила о важности одного компонента над другими. Также было бы невозможно определить 3 различных классификатора ответственности, которые явно выражаются на 3 уровнях. Когда мы связываем класс со слоем, мы явно указываем его роль в решении одной из конкретных обязанностей.
Подобно ситуации с предварительными уровнями, во многих современных программных проектах уровни сами стали очень большими, поскольку они содержат множество классов, и они зависят друг от друга.Иногда этот граф зависимостей настолько сложен, что, естественно, требует разделения слоев на более детализированные подслои. Многие смелые разработчики далеко продвинулись, проявив творческий подход к этому, и добавили много новых уровней в свои приложения. Но в какой-то момент этот подход становится несколько спорным – действительно ли слоев может быть так много? Если да, то почему во всех этих книгах говорится только о трех слоях? а если нет, то как нам справиться сложные графики зависимостей в большом слое?
Решение – Модуль
Если мы просто хотим сгруппировать взаимосвязанные классы вместе, нет необходимости вводить еще один слой.Вместо этого мы можем ввести модуль.
Я называю группу классов модулем, который представляет некоторую функциональность приложения. Я использую термин «компонент» для представления класса или любого другого элемента (например, структуры или перечисления), который сгруппирован внутри модуля. Таким образом, модуль состоит из компонентов. Модуль можно рассматривать как более детализированный уровень приложения.
Модули имеют многие характеристики, аналогичные характеристикам слоя (подробная диаграмма взаимосвязей приведена ниже):
- Модуль может зависеть от других модулей, подобно тому, как уровень может зависеть от других уровней.например ModuleA зависит от ModuleB.
- Компонент может зависеть от других компонентов, если его содержащий модуль зависит от модуля, содержащего другие компоненты. Это похоже на зависимости между слоями. например ComponentA1 может зависеть от ComponentB1, если ModuleA (контейнер ComponentA1) зависит от ModuleB (контейнер ComponentB1). Модуль
- определяет допустимые зависимости для своих компонентов, аналогично тому, как уровень не позволяет своим элементам зависеть от тех, которые находятся на уровнях выше.например ComponentB2 не может зависеть от ComponentA2, потому что ModuleB (контейнер ComponentB2) не зависит от ModuleA (контейнер ComponentA2). Поскольку направление зависимости между модулями-контейнерами является обратным, ComponentA может зависеть от ComponentB, если он решит это сделать.
- Способность определять направления зависимости между модулями – это инструмент, используемый для избежания циклических ссылок между ними (точно так же, как мы не можем и не должны иметь циклических ссылок между уровнями программного обеспечения).Это очень помогает в сложных программных проектах, когда граф зависимостей классов внутри проекта становится запутанным и трудным для понимания с множеством циклических ссылок (голые классы действительно допускают циклические ссылки!). С модулями эта головная боль исчезла – вы должны следовать правильному дизайну из-за ограничений зависимости модуля. В результате у нас есть чистый граф зависимостей классов (то есть компонентов) из коробки.
- Зависимости компонентов внутри модуля разрешены, как и зависимости внутри уровня.например ComponentA1 может зависеть от ComponentA2, поскольку они оба принадлежат одному модулю.
Все эти отношения выражены ниже.
Дополнительные преимущества модуля
Модули обладают дополнительными преимуществами, которыми мы не можем наслаждаться со слоями.
- В отличие от слоев, модули могут иметь отношения “один-несколько”.т.е. один модуль может зависеть от нескольких других модулей. Хотя слои могут делать то же самое, обычно это не очень хорошая идея, потому что тогда заменить слои внизу не так просто, и тогда преимущество разделения слоев несколько теряется. Эмпирическое правило гласит, что слой должен взаимодействовать только со слоем, находящимся прямо под ним.
- Каждый модуль – это функциональность, особенность, чего не скажешь о слоях. Слои обычно состоят из множества различных функций, между которыми могут быть сложные зависимости.Module может избежать таких сложностей, разделившись дальше на несколько модулей и четко определив зависимости между этими новыми модулями. Слои нельзя бесконечно разбивать на новые (именно с этого мы начали в начале этой статьи).
- В многофункциональных приложениях мы теперь можем сосредоточиться на функциях (представляя каждую в виде модуля), а не на слоях (которые ничего не значат для экспертов в предметной области) или на отношениях между классами (что может быть не таким уровнем детализации, который эксперты предметной области понимать).Мы можем визуально нарисовать зависимости между существующими функциями, а также спланировать создание новой функции, найдя для нее подходящее место на графике существующих.
- Мы можем проявлять творческий подход к модулям, позволяя их отключать. Это должно сопровождаться различными классификациями зависимостей модулей, чтобы избежать поломки всей системы, когда один модуль отключен. например зависимость может быть слабой, что означает, что модуль зависимости может быть отключен, но зависимый модуль может терпеть это.Это может устранить необходимость в часто используемом шаблоне переключения функций, когда код становится раздутым из-за условий IF, обертывающих блоки кода, на основе флага, который обычно поступает из файлов конфигурации. При правильно спроектированной системе зависимостей модулей переключение функций становится неявным для разработчиков, если код может допускать нулевые ссылки на компоненты из модулей со слабыми ссылками.
- Возможности безграничны.
Реализации модульной архитектуры
К сожалению, приложения, поддерживающие плагины, называются модульными.Это потому, что эти приложения поддерживают динамическую загрузку новых подключаемых модулей, если все они следуют единой структуре интерфейса, ожидаемой и выполняемой приложением. Я бы предпочел называть эти динамические элементы плагинами , поскольку единообразие интерфейса не так сильно зависит от модулей, хотя оно может быть реализовано и для модулей.
Эта путаница частично виновата в очень небольшом количестве фреймворков приложений, поддерживающих модули, как они объясняются в этой статье.Почти во всех документах, посвященных модульной архитектуре, объясняются плагины (не модули) и способы динамического добавления и загрузки новых плагинов в существующее приложение.
Некоторые из существующих фреймворков (например, require.js) использовали модуль для обозначения чего-то отличного от того, что я объяснил здесь.
Пока что только модуль angular.js наиболее близок к объяснению модуля, которое я дал выше. Тем не менее, это полноценный фреймворк, и выбор – «все или ничего» (если вы используете angular, вам нужно использовать модули).Кроме того, важность модуля либо недостаточно объяснена, либо недостаточно понятна, поскольку в конечном итоге разработчики получают один гигантский угловой модуль, зависящий от всех других существующих модулей в приложении. С другой стороны, я ожидаю, что приложению не обязательно нужен модуль, и он может быть определен только при необходимости (не подход «все или ничего»). Для простых слоев модули не понадобятся. Для сложных и постоянно развивающихся слоев программного обеспечения было бы неплохо иметь модули.
Я до сих пор не могу назвать фреймворк, поддерживающий модульную архитектуру для строго типизированных языков, таких как C # (мой любимый). Надеюсь, он где-то там, а просто я его еще не нашел.
Видео по теме: Модульная архитектура программного обеспечения
Заключение
Я постарался объяснить как можно больше в одной статье.Я освещаю гораздо больше в специальных учебных курсах, которые я провожу, поэтому обязательно ознакомьтесь с ними для своих команд.
Об авторе и содержании
Автором вышеупомянутого контента является Тенгиз Тутисани – владелец и технический руководитель Tutisani Consulting.
Если вы согласны с изложенными мыслями и хотите узнать больше, вот несколько предложений:
Давайте поговорим!
Взгляд за шумихой: действительно ли модульная монолитная программная архитектура мертва? | Автор: Md Kamaruzzaman
В 2010-х годах многие компании, занимающиеся веб-масштабированием, такие как Netflix, Amazon, Spotify, Uber , предъявляли особые требования: масштабирование приложений, масштабирование разработки, сокращение времени выхода на рынок.Они также обнаружили, что существующая модульная монолитная архитектура или сервис-ориентированная архитектура (SOA) не могут удовлетворить их требования. В результате в 2012 году родился новый стиль архитектуры программного обеспечения: Microservice Software Architecture .
С тех пор популярность микросервисов резко возросла с большим количеством фанфар и оптимизма. Конференции наполнены разговорами и семинарами по микросервисам. Как мы слишком часто видели, шумихи и мифы объединяются .
Микросервисная архитектура – правильный выбор для многих случаев использования.Но, как и у любой другой архитектуры программного обеспечения, у нее также есть слабые места (где она лучше всех) и критические ситуации (где она терпит неудачу).
К сожалению, многие люди думали, что Microservices – это Silver Bullet , которая решает все проблемы разработки программного обеспечения. Они также отказались от других архитектурных стилей, таких как модульная монолитная архитектура. Кроме того, как и в случае любой разрекламированной технологии, некоторые люди думали о микросервисах как о « Golden Hammer » и пытались использовать их во всех видах разработки программного обеспечения, не задумываясь о контексте.
Очарованные новым блестящим микросервисом, люди говорили о модульной монолитной архитектуре программного обеспечения как об ужасном архитектурном стиле , который скоро умрет и которому нет места в современной разработке программного обеспечения. Кроме того, если вы являетесь разработчиком программного обеспечения или архитектором программного обеспечения, а говорит о модульной монолитной архитектуре программного обеспечения, тогда в вашей компании вы будете превосходить . Ваши коллеги будут рассматривать вас как парня старой закалки, который сдерживает модернизацию программного стека.
С другой стороны, если вы упомянете термин «микросервисная архитектура» на совещаниях по проектированию, то ваши коллеги будут смотреть на вас с огромным уважением и трепетом.
Обоснована ли вся эта критика в отношении модульной монолитной архитектуры программного обеспечения? Он мертв и ему нет места в современной разработке программного обеспечения в эпоху Docker, Kubernetes, Cloud, Big Data и более быстрого цикла выпуска?
В этой статье я более подробно рассмотрю модульную монолитную архитектуру программного обеспечения и ее актуальность в современной среде разработки программного обеспечения.
С первых дней разработки программного обеспечения (1950-е годы) программные системы разрабатывались как единая система и развертывались как единый процесс. Такие программные системы обозначаются как Монолитные программные системы . Вот пример классического монолитного веб-приложения:
Монолитное веб-приложениеВ приведенном выше проекте все устройство разделено на несколько уровней (презентация, бизнес, постоянство), и все приложение развертывается на сервере приложений / веб-сервере. .
По мере того, как программная система становилась все более сложной (с 1970-х годов), инженеры-программисты решили эту сложность, разложив целые системы на модули « Слабо связанные, высокосвязные ». Эта система известна как модульная монолитная программная архитектура . Вот мое определение модульной монолитной программной архитектуры:
Программная система, которая может состоять из слоев или шестиугольных компонентов, и каждый слой или шестиугольный компонент затем раскладывается на «слабосвязанные, высокосвязные модули», но вся система развертывается как все это известно как модульная монолитная архитектура программного обеспечения.
Вот пример модульной монолитной архитектуры в большом и сложном веб-приложении: Модульное монолитное веб-приложение
, автор Md KamaruzzamanВ приведенном выше случае каждый уровень разбит на несколько « слабосвязанных, высокосвязных » модули (например, библиотеки Java), которые связаны внутренне (через вызовы методов или вызовов функций), зависят от языка.
Вот характеристики модульной монолитной архитектуры :
- Полная программная система развернута как единое целое (все или ничего)
- Модульная граница является внутренней и может быть легко пересечена, что может привести к спагетти-коду (как показано выше желтыми линиями)
- Приложение работает как единый процесс
- Один размер для всех, т.е.е., одно решение для всех размеров приложения
- Отсутствие строгого владения данными между модулями
Как и все архитектурные стили, модульная монолитная архитектура имеет преимущества и недостатки, о которых я кратко расскажу.
Плюсы:
- Monolith имеет несколько движущихся частей (например, один процесс, один сервер приложений, одна база данных). В результате проще проектировать, развертывать и тестировать (системный тест, тест e2e) монолитное приложение.
- Из-за меньшего количества движущихся частей у него на меньшая площадь поверхности для атаки .В результате проще защитить монолитное приложение.
- Низкая операционная сложность
- Монолитное приложение имеет одну единую базу данных OLTP. В результате, легче управлять транзакциями и обменом данными .
Минусы:
- Из-за общей кодовой базы (которая часто является кодом спагетти) и общего источника данных, трудно распараллелить работы между несколькими командами. Итак, масштабирование разработки ужасное.
- Большая монолитная кодовая база (часто спагетти-код) ставит огромную когнитивную сложность на голову разработчика. В результате скорость разработки оставляет желать лучшего.
- Детальное масштабирование (т. Е. Масштабирование части приложения) невозможно.
- Программирование полиглота или база данных полиглота – сложная задача.
- Модернизация затруднена из-за монолитного характера приложений «Все или ничего».
В 2010-х годах компании Web-Scale обнаружили, что для очень больших приложений архитектура Modular Monolithic Software не подходит, и создали Microservice Software Architecture .Вот мое определение микросервисов:
Архитектура микросервисов также разделяет большие сложные системы по вертикали (по функциональным или бизнес-требованиям) на более мелкие подсистемы, которые являются процессами (следовательно, развертываются независимо), и эти подсистемы взаимодействуют друг с другом. через легкие, не зависящие от языка сетевые вызовы (например, REST, gRPC)
Если мы рассмотрим наше предыдущее большое и сложное веб-приложение, то вот архитектура этого приложения на основе микросервисов:
Архитектура микросервисов от Md KamaruzzamanВот характеристики микросервисной архитектуры :
- Все приложение разделено на отдельные процессы, каждый из которых может содержать несколько модулей .
- В отличие от модульных монолитов или SOA, приложение микросервиса разделено на вертикально (в зависимости от функциональности или доменов)
- Граница микросервиса является внешней . В результате микросервисы взаимодействуют друг с другом посредством сетевых вызовов.
- Вместо одной базы данных каждая микрослужба имеет свою базу данных .
- Дополнительная синхронизация данных требуется из-за «базы данных на микросервис».
В предыдущем посте я подробно рассмотрел микросервисную архитектуру:
Вопреки шумихе и мифам, микросервисы имеют много преимуществ и справедливую долю недостатков:
Плюсы:
- Лучшее масштабирование разработки , поскольку команды могут работать параллельно над разными микросервисами автономно с небольшой внешней зависимостью.
- Размер микросервисов очень мал.Это возлагает на низкую когнитивную сложность на голову разработчика , и разработчики становятся более продуктивными.
- Поскольку каждый микросервис представляет собой отдельный процесс, его можно развернуть независимо. В результате микросервисная архитектура дает более быстрый цикл выпуска .
- Гранулярное масштабирование , то есть масштабирование части приложения, возможно.
- Детальное владение данными, поскольку каждая микрослужба имеет свою базу данных
- Пока сохраняется внешний контракт, микросервис можно быстро заменить, как блоки Lego.Итак, приложение Microservice проще модернизировать .
Минусы:
- Разделение всей системы по вертикали – это искусство, а не наука, которая требует особого мастерства. Кроме того, непростая задача – разбить одну базу данных на несколько баз данных, а затем обмениваться данными между ними. Итак, проектировать всю систему сложнее .
- Сложность кода часто заменяется на , операционная сложность .
- Из-за нескольких баз данных (которые обычно распределены) совместное использование данных и управление транзакциями являются очень сложной задачей.
- Из-за множества движущихся частей (многие процессы, базы данных, сетевые вызовы, контейнеры, виртуальные машины) полное приложение намного сложнее защитить .
- Из-за вызовов внешней сети общая задержка всего приложения намного выше .
Одним словом, ответ: Нет . В недавнем интервью с подкастом Go Time гуру облаков и Kubernetes Келси Хайтауэр предсказал возвращение модульной монолитной архитектуры в ближайшие годы.Кроме того, в предыдущем посте « 20 прогнозов тенденций разработки программного обеспечения в 2020 году, » я предсказал растущую тенденцию к использованию модульных монолитов. Существует также множество статей , в которых компании написали, как их попытка перенести микросервисную архитектуру потерпела неудачу, и они перешли на монолитную архитектуру программного обеспечения .
Когда микросервисы впервые появились на сцене, многие люди просто увлеклись и думали, что это «единая архитектура , которая управляет всеми». Они думали, что микросервисная архитектура – это серебряная пуля, которая может решить все организационные ограничения и технические сложности программной системы, и попытались использовать ее повсюду. В каком-то смысле это напоминает мне обсуждение SQL / NoSQL .
В течение 2010-х годов, когда на сцену вышла NoSQL, многие люди обсуждали, что SQL устарел как технология и не имеет места в отрасли . В конце концов, NoSQL предлагает горизонтальное масштабирование и используется такими компаниями, как Google, Facebook, Amazon.Таким образом, они приняли базы данных NoSQL, не думая, что их вариант использования отличается от вариантов использования Google или Facebook. Вскоре компании на собственном горьком опыте убедились, что они не могут заменить свои транснациональные базы данных SQL базами данных NoSQL, отличными от ACID. По мере того, как шумиха улеглась, мы теперь знаем, что отрасли нужны как базы данных OLTP (SQL), так и базы данных OLAP (NoSQL) .
Здесь я перечисляю причины, по которым модульная монолитная архитектура программного обеспечения по-прежнему актуальна в современной разработке программного обеспечения и скоро не исчезнет:
- Разнообразие приложений: Многие крупные корпорации и компании веб-масштаба нуждаются в микросервисной архитектуре.Но есть также много компаний, для которых микросервисная архитектура – неправильный выбор. Для них модульная монолитная архитектура – лучший выбор. Современный ландшафт прикладных программ весьма разнообразен. . В нем есть места как для модульной монолитной архитектуры, так и для микросервисной архитектуры.
- Унифицированное решение : Одна из самых сильных сторон модульной монолитной программной архитектуры заключается в том, что она дает решение, прошедшее проверку временем. Если он соответствует размеру приложения, то Ruby on Rails или Spring Boot предоставляет набор четко определенных и стандартных шаблонов для разработки приложения.Напротив, микросервисная архитектура похожа на дикий запад и всегда зависит от многих факторов (размера приложения, контекста). При отсутствии тщательного проектирования микросервисы могут быстро превратиться в «распределенный монолит » со всеми недостатками монолита и всеми сложностями микросервисов.
- Ноу-хау: Модульная монолитная архитектура программного обеспечения существует с 1970-х годов. , и большинство разработчиков знают, как разрабатывать модульную монолитную архитектуру программного обеспечения. Микросервисы относительно новые и испытывают нехватку специалистов . Кроме того, вертикальная декомпозиция приложения – это искусство, а не наука, и требует большого мастерства и практики. Многие компании могли бы разрабатывать программное обеспечение быстрее с помощью проверенной модульной монолитной архитектуры программного обеспечения, а не новой программной архитектуры Microservice. Конечного пользователя не волнует базовая архитектура или технология; все он заботится о функциональности.
Здесь я перечисляю некоторые варианты использования, в которых модульная монолитная программная архитектура будет использоваться в 2020 и далее :
Малое и простое приложение
Источник: Мартин ФаулерКак первый специалист по микросервисам показал Мартин Фаулер , Модульный Монолитная программная архитектура – лучший выбор для приложений определенного размера и сложности .С точки зрения производительности разработчика, приложение Ruby on Rails или Spring Boot до определенного размера может легко превзойти сложную микросервисную архитектуру. Если в компании одна команда разработчиков (6–8 разработчиков), то им следует использовать модульную монолитную архитектуру программного обеспечения.
Современные модульные монолиты
К сожалению, за последнее десятилетие в модульных монолитах было мало инноваций, так как они, вероятно, ждали смерти. Но поскольку Modular Monoliths пережил натиск микросервисов, мы можем ожидать здесь некоторых инноваций.У микросервисов есть много новых концепций, и Monoliths могут это принять.
Одним из таких современных фреймворков Modular Monolith является Inertia.js . Он объединил в себе простую и высокопроизводительную платформу для серверной веб-разработки, такую как Ruby On Rails, Django, с SPA на основе JavaScript, например React, Vue . Хитрость в том, что они объединили лучшее из обоих миров с любым API.
Более подобный фреймворк значительно ускорит разработку программного обеспечения Modular Monolithic.
Приложения Brownfield
Микросервисы отлично подходят для приложений Greenfield. Но часто компании уже имеют существующих плохо спроектированных монолитных приложений . Один из способов справиться с существующим монолитным приложением – вывести его из эксплуатации и разработать новые микросервисы. Все мы знаем, что списать работающее приложение невозможно. Кроме того, будет сложно заменить это приложение новыми микросервисами (которые будут страдать от младенческих проблем).Лучшим подходом может быть рефакторинг плохо спроектированного монолитного приложения в модульное монолитное приложение и сохранение его как есть.
Приложения со сложным доменом
Микросервисы – это все о разделении сложной системы по вертикали, т. Е. Разделении в соответствии с логикой домена. Иногда, есть приложения, в которых домены запутаны, и распутать домены сложно. Если запутанные домены разделены на микросервисы, это приведет к распределенному монолиту со всеми недостатками монолита и микросервисов.В таком сценарии Modular Monolith, вероятно, является лучшим злом.
Не для бизнеса, специальные приложения
Не все приложения являются корпоративными. Есть много приложений (например, телекоммуникации, автомобилестроение), где задержка и более быстрый ответ более важны. Кроме того, существует множество конкретных областей (например, машинное обучение, глубокое обучение, хранилище данных), где пропускная способность ЦП или пропускная способность сети являются наиболее важными критериями. В этих областях модульная монолитная архитектура программного обеспечения будет иметь преимущество перед микросервисами.
Внутренний инструмент
У каждой компании есть внутренние инструменты. Обычно эти инструменты не пострадают от нерегулируемого роста. Для внутренней разработки инструментов модульная монолитная архитектура программного обеспечения будет лучшим выбором по сравнению с архитектурой микросервисов.
Модули против микросервисов – O’Reilly
Многое было сказано о переходе от монолитов к микросервисам. Помимо приятного скатывания с языка, также кажется несложным делом разделить монолит на микросервисы.Но действительно ли этот подход является лучшим выбором для вашей организации? Это правда, что у поддержки беспорядочного монолитного приложения есть много недостатков. Но есть убедительная альтернатива, о которой часто забывают: разработка модульных приложений. В этой статье мы исследуем, что влечет за собой эта альтернатива, и покажем, как она связана с созданием микросервисов.
Микросервисы для модульности
«С помощью микросервисов мы, наконец, можем заставить команды работать независимо» или «наш монолит слишком сложен, что тормозит нас.Эти выражения – лишь некоторые из многих причин, по которым команды разработчиков выбирают микросервисы. Другой – необходимость масштабируемости и устойчивости. Кажется, что коллективные разработчики стремятся к модульному подходу к проектированию и разработке системы. Модульность в разработке программного обеспечения можно свести к трем руководящим принципам:
Учись быстрее. Копай глубже. Смотрите дальше.
- Сильная инкапсуляция : скрыть детали реализации внутри компонентов, что приведет к слабой связи между различными частями.Команды могут работать изолированно над изолированными частями системы.
- Четко определенные интерфейсы : вы не можете скрыть все (иначе ваша система не будет делать ничего значимого), поэтому четко определенные и стабильные API-интерфейсы между компонентами являются обязательными. Компонент может быть заменен любой реализацией, соответствующей спецификации интерфейса.
- Явные зависимости : наличие модульной системы означает, что отдельные компоненты должны работать вместе. Вам лучше иметь хороший способ выразить (и подтвердить) их отношения.
Многие из этих принципов можно реализовать с помощью микросервисов. Микросервис может быть реализован любым способом, если он предоставляет четко определенный интерфейс (часто REST API) для других сервисов. Детали его реализации являются внутренними для службы и могут изменяться без общесистемного воздействия или координации. Зависимости между микросервисами обычно не совсем явны во время разработки, что приводит к возможным сбоям оркестровки служб во время выполнения. Скажем так, последний принцип модульности может быть использован в большинстве микросервисных архитектур.
Итак, микросервисы реализуют важные принципы модульности, что приводит к ощутимым преимуществам:
- Команды могут работать и масштабироваться независимо.
- Микросервисы небольшие и целенаправленные, что снижает сложность.
- Услуги могут быть изменены или заменены внутри компании без глобального воздействия.
Что не нравится? Что ж, по пути вы перешли от единственного (хотя и немного тяжелого) приложения к распределенной системе микросервисов. Это вносит огромную операционную сложность в таблицу.Внезапно вам нужно постоянно развертывать множество различных (возможно, контейнерных) сервисов. Возникают новые проблемы: обнаружение сервисов, распределенное ведение журнала, трассировка и так далее. Теперь вы еще больше подвержены ошибкам распределенных вычислений. Версионирование интерфейсов и управление конфигурацией становятся серьезной проблемой. У этого списка нет конца.
Оказывается, соединения между микросервисами столь же сложны, как и объединенная бизнес-логика всех отдельных микросервисов.И чтобы попасть сюда, нельзя просто взять монолит и порубить его. В то время как «спагетти-код» в монолитных базах кода проблематичен, установка сетевой границы между ними обостряет эти проблемы запутывания до совершенно болезненных.
Модульная альтернатива
Означает ли это, что мы либо низведены до беспорядочного монолита, либо должны утонуть в сложности безумия микросервисов? Модульность может быть достигнута и другими способами. Важно то, что мы можем эффективно проводить границы во время разработки.Но мы можем добиться этого и за счет создания хорошо структурированного монолита. Конечно, это означает использование любой помощи, которую мы можем получить от языка программирования и инструментов разработки, для обеспечения соблюдения принципов модульности.
В Java, например, есть несколько систем модулей, которые могут помочь в структурировании приложения. OSGi – наиболее известная из них, но с выпуском Java 9 в саму платформу Java добавлена собственная модульная система. Модули теперь являются частью языка и платформы как первоклассная конструкция.Модули Java могут выражать зависимости от других модулей и публично экспортировать интерфейсы, строго инкапсулируя классы реализации. Даже сама платформа Java (огромная кодовая база) была разбита на модули с использованием новой модульной системы Java. Вы можете узнать больше о модульной разработке с использованием Java 9 в моей будущей книге «Модульность Java 9», которая теперь доступна в раннем выпуске.
Другие языки предлагают аналогичные механизмы. Например, с ES2015 в JavaScript появилась модульная система. До этого Node.js уже предлагал нестандартную модульную систему для серверной части JavaScript. Однако, как динамический язык, JavaScript имеет более слабую поддержку для обеспечения интерфейсов (типов) и инкапсуляции между модулями. Вы можете рассмотреть возможность использования TypeScript поверх JavaScript, чтобы снова вернуть это преимущество. Microsoft .Net Framework имеет строгую типизацию, как Java, но не имеет прямого эквивалента будущей модульной системе Java с точки зрения строгой инкапсуляции и явных зависимостей между сборками.Тем не менее, хорошая модульная архитектура может быть достигнута с помощью шаблонов инверсии управления, которые стандартизированы в .Net Core, и путем создания логически связанных сборок. Даже C ++ рассматривает возможность добавления модульной системы в будущую версию. Многие языки получают признание за модульность, что само по себе является выдающимся достижением.
Когда вы сознательно стараетесь использовать возможности модульности своей платформы разработки, вы можете добиться тех же преимуществ модульности, которые мы ранее приписывали микросервисам.По сути, чем лучше система модулей, тем большую помощь вы получите во время разработки. Разные команды могут работать над разными частями, где только четко определенные интерфейсы являются точками соприкосновения между командами. Тем не менее, во время развертывания модули объединяются в единый модуль развертывания. Таким образом можно предотвратить существенную сложность и затраты, связанные с переходом на разработку и управление микросервисами. Верно, это означает, что вы не можете построить каждый модуль на отдельном технологическом стеке. Но действительно ли ваша организация готова к этому?
Модули проектирования
Создание хороших модулей требует такой же строгости проектирования, как и создание хороших микросервисов.Модуль должен моделировать (часть) единственного ограниченного контекста домена. Выбор границ микросервисов является важным с архитектурной точки зрения решением, которое в случае неправильной реализации может повлечь за собой дорогостоящие последствия. Границы модулей в модульном приложении изменить легче. Рефакторинг между модулями обычно поддерживается системой типов и компилятором. Изменение границ микросервисов требует интенсивного межличностного общения, чтобы не допустить взрыва во время выполнения. И честно говоря, как часто вы правильно понимаете свои границы в первый раз или даже во второй?
Во многих отношениях модули на языках со статической типизацией предлагают лучшие конструкции для четко определенных интерфейсов.Вызов метода через типизированный интерфейс, предоставляемый другим модулем, гораздо более устойчив к изменениям, чем вызов конечной точки REST на другом микросервисе. REST + JSON распространен повсеместно, но он не является признаком хорошо типизированной совместимости при отсутствии (проверенных компилятором) схем. Добавьте к этому тот факт, что прохождение сети, включая (де) сериализацию, по-прежнему не является бесплатным, и картина станет еще более мрачной. Более того, многие модульные системы позволяют выражать ваши зависимости от других модулей.Когда эти зависимости нарушаются, модульная система этого не допустит. Зависимости между микросервисами материализуются только во время выполнения, что затрудняет отладку систем.
Модулитакже являются естественными единицами для владения кодом. Команды могут нести ответственность за один или несколько модулей в системе. Единственное, что разделяют с другими командами, – это публичный API их модулей. Во время выполнения между модулями меньше изоляции по сравнению с микросервисами. В конце концов, все по-прежнему выполняется в одном процессе.
Нет причин, по которым модуль в монолите не может владеть своими данными, как это делает хороший микросервис. В этом случае совместное использование в модульном приложении происходит через четко определенные интерфейсы или сообщения между модулями, а не через общее хранилище данных. Большая разница с микросервисами заключается в том, что все происходит в процессе. Не следует недооценивать возможные проблемы согласованности. С модулями конечная согласованность может быть осознанным стратегическим выбором. Или вы можете просто «логически» разделить данные, сохранив их в одном хранилище данных, и при этом пока что использовать междоменные транзакции.Для микросервисов нет выбора: конечная согласованность – это данность, и вам нужно адаптироваться.
Когда микросервисы подходят вашей организации?
Итак, когда вам следует обратиться к микросервисам? До сих пор мы в основном фокусировались на решении сложных задач за счет модульности. Для этого подойдут как микросервисы, так и модульные приложения. Но есть и другие вызовы, помимо тех, которые были решены до сих пор.
Когда ваша организация находится в масштабе Google или Netflix, имеет смысл использовать микросервисы.У вас есть возможность создавать свою собственную платформу и наборы инструментов, а количество инженеров запрещает любой разумный монолитный подход. Но большинство организаций не работают в таком масштабе. Даже если вы думаете, что ваша организация однажды станет единорогом на миллиард долларов, начало работы с модульным монолитом не принесет большого вреда.
Еще одна веская причина для развертывания отдельных микросервисов заключается в том, что разные сервисы по своей сути лучше подходят для разных технологических стеков. Опять же, у вас должен быть масштаб, чтобы привлекать таланты из этих разрозненных стеков и поддерживать эти платформы в рабочем состоянии.
Микросервисытакже обеспечивают независимое развертывание различных частей системы, что сложнее (или даже невозможно) на большинстве модульных платформ. Изолированные развертывания повышают устойчивость и отказоустойчивость системы. Кроме того, характеристики масштабирования могут быть разными для каждой микрослужбы. На подходящем оборудовании могут быть развернуты разные микросервисы. Модульный монолит также можно масштабировать по горизонтали, но вы масштабируете все модули вместе. Это не всегда может сработать к лучшему, хотя на практике с таким подходом можно далеко уйти.
Заключение
Как всегда, лучший вариант – найти золотую середину. Есть место для обоих подходов, и какой из них лучше всего зависит от среды, организации и самого приложения. Почему бы не начать с модульного приложения? Вы всегда можете перейти на микросервисы позже. Тогда вместо того, чтобы хирургическим путем распутывать монолит, у вас уже есть разумные границы модуля. Это даже не исключительный выбор: вы также можете использовать модули для внутренней структуры микросервисов.Тогда возникает вопрос, почему микросервисы должны быть «микро»?
Даже если вы откажетесь от единого модульного приложения, ваши сервисы не обязательно должны быть крошечными, чтобы их можно было сопровождать. Опять же, применение принципов модульности в сервисах позволяет им масштабироваться по сложности, превышающей то, что вы обычно приписываете микросервисам. На этой картинке есть место как для модулей, так и для микросервисов. Реальной экономии можно добиться за счет уменьшения количества сервисов в вашей архитектуре.Модули могут помочь структурировать и масштабировать сервисы так же, как они могут помочь структурировать единое монолитное приложение.
Если вам нужны преимущества модульности, убедитесь, что вы не обманываете себя, ориентируясь только на микросервисы. Изучите внутрипроцессные функции модульности или фреймворки вашего любимого технологического стека. Вы получите поддержку по внедрению модульного дизайна, вместо того чтобы полагаться только на условные обозначения, чтобы избежать спагетти-кода. Затем сделайте осознанный выбор, хотите ли вы понести сложность микросервисов.Иногда вам просто нужно, но часто вы можете найти лучший путь вперед.
Прочтите «Микросервисы: быстрое и простое определение», чтобы получить базовый обзор микросервисов и рекомендуемых ресурсов.
Модульная архитектура приложения – Введение – Асмир Мустафик
При разработке программного обеспечения иногда нам нужно разрешить нашему приложению иметь плагины или модули, разработанные третьими сторонами. Создание надежной архитектуры, позволяющей создать мощный механизм, может оказаться сложной задачей.В этой серии публикаций мы увидим некоторые стратегии для этого.
Это первый пост из серии постов, в которых будут описаны стратегии построения модульные и расширяемые приложения. (по мотивам выступления qafoo в 2011 году в Берлине)
При разработке программного обеспечения одним из наиболее распространенных шагов является обеспечение возможности расширения и расширения конечного приложения. модульный.
Предположим, у нас есть приложение или библиотека. Если мы смотрим на это со стороны, часто это выглядит как единое целое.При более внимательном рассмотрении можно выделить разные и более или менее независимые наборы компонентов. Компоненты могут быть действительно взаимосвязаны и иметь зависимости с остальной частью приложения. и для их разработки может потребоваться глубокое знание остальной части приложения.
По мере роста приложения мы можем продолжать добавлять компоненты … но за это приходится платить. Компоненты часто слишком много знают о нашем приложении, и между ними существует хрупкое равновесие зависимостей. и наше приложение.При неосторожном обращении небольшое изменение в одном компоненте может потребовать изменений во многих других.
Как правило, я лично стараюсь как можно больше следовать Принцип ациклических зависимостей
Еще один способ обеспечить расширяемость, но сохранить приложение «чистым» – это ввести модули.
Модули
Модули – это «компоненты», разработанные вне приложения. Модули связываются с приложением только через определенные точки входа.
Разные люди используют разные имена для модулей, таких как плагины, бандлы, надстройки и так далее … но основная идея всегда одна и та же, независимые функции, разработанные вне приложения.
Почему?
Используя модули, которые не являются частью приложения, мы получаем следующие преимущества:
- Настройки : приложение может вести себя по-другому, просто включив / отключив некоторые модули.
- Меньше зависимостей : модули более независимы от самого приложения, пока «точки входа» не станут совместимость, оба модуля и приложение могут развиваться независимо.
- Сторонние расширения : поскольку модули не являются частью приложения и “точки входа” четко определены, разработка модулей может выполняться третьими сторонами.
- Независимая разработка : Поскольку приложение и модули независимы, они могут быть:
- разработано сторонними разработчиками
- выпущен с независимыми циклами выпуска
- потенциально разработано с использованием различных технологий
- Приложение меньшего размера Приложение меньшего размера (многие функции могут быть реализованы с помощью модулей) и меньшее приложение переводится в лучшую ремонтопригодность.
Просто приведу несколько примеров, чтобы понять, почему важно иметь приложение, которое позволяет использовать модули:
- WordPress это самая популярная платформа для ведения блогов в настоящее время. Часть его успеха – невероятно мощный и в то же время невероятно простой плагин и система тем.
- Symfony – популярный фреймворк PHP. Благодаря системе «связок» можно получить большой выбор готовых функциональность практически без усилий.
- PHP , сам по себе предлагает отличный набор расширений, и эти расширения позволяют интегрировать язык с большим разнообразие систем.
Решаемые задачи
Чтобы сделать наше приложение модульным, мы должны тщательно решить, какие модули должны уметь, как будут взаимодействовать с приложением и как раскрывать их функции. При реализации подключаемой / модульной системы мы должны учитывать, какая часть поведения приложения модуль будет разрешено изменять и в какой мере.
Например, если мы разрабатываем текстовый процессор, модуль может добавить только поддержку нового формата файла или просто новый значок на панели инструментов или на противоположной стороне, чтобы полностью изменить все приложение.
В зависимости от этого решения мы можем спроектировать наш модуль по-разному, но почти всегда нам придется иметь дело со структурой модуля, регистрацией / конфигурацией, управлением ресурсами и связью с ядром.
1. Структура модуля
Отправной точкой является структура модуля, такая как именование файлов, структура папок, именование классов и т. Д.Когда структура модуля определена, остальные аспекты сильно зависят.
Часто структура модуля является первой точкой входа в приложение.
Мое личное предложение – не навязывать какую-либо конкретную структуру папок, а иметь единственную «точку входа», где модуль загружен и использует эту точку входа как источник истины и конфигурации. Значение «точки входа» будет определено в следующем параграфе.
2. Регистрация
Когда структура модуля определена, следующим шагом будет сообщить об этом нашему приложению.
В основном это можно сделать двумя способами:
- обнаружение : наше приложение может попытаться использовать предопределенный набор «правил» для поиска новых модулей и загрузки / регистрации их.
В качестве примера можно попробовать поискать в конкретных папках некоторые конкретные файлы или проверьте, определен ли конкретный класс (классы) , и попробуйте создать его экземпляр. - конфигурация : мы можем явно настроить приложение для загрузки конкретных файлов или особого класса (ов) .
Нет предпочтительных способов сделать это, это действительно зависит от вашего приложения. регистрация на основе “конфигурации” может быть лучше, если ваша аудитория более технична, а подход “открытия” может предложить более плавный пользовательский интерфейс (но может быть сложнее реализовать).
Мое личное предложение – снова создать единую «точку входа», которая будет регистрировать модуль в ядре приложения, может быть одним файлом, классом, строкой базы данных, именем службы и т. д…
Приложение предлагает один или несколько «интерфейсов» для взаимодействия со своим «ядром», и они используются через «точки входа». Под «интерфейсом» здесь подразумевается любой возможный протокол или соглашение, определенное приложением. который может быть использован модулем для достижения цели.
Примеры:
- composer : композитор добавляет функциональные возможности с помощью discovery .
Composer будет искать установленные пакеты, имеющиеtype = composer-plugin, будет искать свойство с именемclassопределено в файле composerпакета.jsonи зарегистрирует прослушиватели событий, объявленные этим классом. Более подробная информация о нем доступна здесь - symfony : Symfony добавляет функциональность с помощью конфигурации .
ВAppkernelкласс необходим для определения всех “пакетов”, которые будут использоваться symfony для обогащения функциональные возможности фреймворка. Будет создан экземпляр класса “bundle”, который отвечает за регистрацию пакета. в точки расширения, которые допускает Symfony.Класс пакета может изменять практически любую часть самой symfony, поскольку у него есть доступ к механизм внедрения зависимостей ядра Symfony. Более подробная информация об этом доступна здесь. Недавно с помощью flex стали доступны автоматическое обнаружение и настройка. - laravel : способ добавления функций в laravel – это discovery .
Laravel будет искать установленные пакеты и искать свойство с именемextra.Ларавелопределено в файле composerпакета.jsonи зарегистрирует объявленных в нем поставщиков услуг. Более подробная информация о нем доступна здесь
3. Конфигурация
Когда модуль зарегистрирован в ядре, может быть полезно разрешить некоторые дополнительные конфигурации.
Скорее всего, приложение каким-то образом настроено в соответствии с ожиданиями пользователей, должно произойти то же самое.
для модуля.
Можно предложить различные стратегии конфигурации, мое личное предложение – предложить конфигурацию механизм очень близок к тому, как настроено приложение.Если приложение настроено с помощью файлов конфигурации, переменных среды, записей базы данных или неплохая панель управления, модуль настраивается аналогично
Хорошая функция, которую модули должны иметь (и приложение должно разрешать) – это “значения по умолчанию”, поэтому практически модуль может не требует настройки.
Примеры:
- composer : файл composer
composer.jsonпозволяет вам решать, какие плагины загружать, какие команды запускать и так далее. - symfony : symfony позволяет использовать YAML, XML и PHP в качестве языков конфигурации,
значения конфигурации могут быть объявлены в конфигурации
(yml | xml | php)(и в некоторых других местах), и пакеты могут предоставить для нее значения по умолчанию. - laravel : laravel использует в основном PHP в качестве языка конфигурации и благодаря этому можно использовать мощь синтаксиса PHP при определении конфигураций.
4. Ресурсы
Некоторым модулям может потребоваться предоставить пользователю некоторый контент в виде изображений, CSS, шаблонов, переводов, файлов и т.п.Приложения могут использовать разные способы предоставления контента пользователю.
Когда ресурс «управляется приложением», просто об использовании “интерфейса приложения” для предоставления / переопределения ресурса (как пример с использованием интерфейса плагина приложения).
Когда ресурсы не управляются приложением, а относятся к конкретному модулю, можно получить больше сложный. Некоторые способы справиться с этим:
- создание ссылок / копирование содержимого в веб-каталог
- требует некоторого шага для публикации ресурсов
- обслуживает ресурсы с помощью приложений, например pipe-it через PHP
- может быть медленным или ресурсоемким
- настроить веб-сервер для явного обслуживания ресурсов плагина
- напрасно воплощает идею «plug & play», стоящую за модулями, добавляя дополнительные конфигурации
позволяет пользователю «копировать и вставлять» ресурсы вручную
У каждого варианта есть свои недостатки и достоинства.В последнее время наиболее популярной является стратегия «связывание / копирование».
5. Взаимодействие с приложением
Теперь, когда модуль загружен и настроен, все готово.
Приложение может определить все точки «взаимодействия» и пройти проверку модулей, если какой-то модуль «заинтересован»
при взаимодействии с ядром приложения (вероятно)
Существует множество стратегий “взаимодействия” с приложением, некоторые из них ограничивают способность модуля взаимодействовать. на определенной (определяемой пользователем) части, если приложение, в то время как другое, может позволить потенциально изменить все поток приложений.
В следующих статьях мы более подробно рассмотрим возможные способы взаимодействия с приложением.
Заключение
В этой первой статье я описал некоторые мотивы и проблемы при создании расширяемых приложений. В следующих статьях мы увидим некоторые стратегии взаимодействия с приложением как хуки , менеджер событий , шаблон наблюдателя , наследование и другие.
Жду ваших отзывов.
php, расширяемость, плагины, хуки, api, программный дизайн, программная архитектура, модули, ядро
Паттерны модульной архитектуры – DZone Refcardz
Фреймворки модулейнабирают обороты на платформе Java. Хотя модульность не нова, она обещает изменить способ разработки программных приложений.Вы сможете осознать преимущества модульности, только если поймете, как разрабатывать более модульные программные системы.
Шаблоны модульности закладывают основу, необходимую для включения модульного дизайнерского мышления в ваши инициативы по разработке. Для использования этих шаблонов не требуется никакой модульной структуры, и у вас уже есть многие инструменты, необходимые для разработки модульного программного обеспечения. Эта карточка содержит краткий справочник по 18 шаблонам модульности, обсуждаемым в книге Архитектура приложений Java: Шаблоны модульности с примерами с использованием OSGi.
Шаблоны модульности не относятся к платформе Java. Их можно применять на любой платформе, рассматривая единицу выпуска и развертывания как модуль. Каждый шаблон включает схему (кроме базовых шаблонов), описание и руководство по реализации.
Базовые шаблоны: Фундаментальные концепции модульного дизайна, на основе которых существует несколько других шаблонов.
Шаблоны зависимостей: Используется, чтобы помочь вам управлять зависимостями между модулями.
Шаблоны удобства использования: Используются для помощи в разработке простых в использовании модулей.
Шаблоны расширяемости: Используются для помощи в разработке гибких модулей, которые можно расширить с помощью новых функций.
Служебные шаблоны: Используются в качестве инструментов для модульной разработки.
Сравнение логической и модульной конструкции
Практически все известные принципы и шаблоны, которые помогают при разработке программного обеспечения, обращаются к логическому проектированию. Идентификация методов класса, отношений между классами и структуры пакета системы – все это проблемы логического проектирования.Подавляющее большинство команд разработчиков тратят свое время на решение логических проблем проектирования. Гибкий логический дизайн упрощает обслуживание и увеличивает расширяемость.
Однако логическое проектирование – это всего лишь одна часть проблемы проектирования и архитектуры программного обеспечения. Другой – модульный дизайн, в котором основное внимание уделяется физическим объектам и отношениям между ними. Выявление сущностей, содержащих ваши логические конструкции, и управление зависимостями между единицами развертывания – это примеры модульной конструкции.Без модульной конструкции вы можете не реализовать преимущества, которые ожидаете от логической конструкции. Шаблоны модульности помогут вам:
- Разрабатывать программное обеспечение, которое можно расширять, использовать повторно, поддерживать и адаптировать.
- Разрабатывайте модульное программное обеспечение сегодня, в ожидании будущей поддержки модульности платформ.
- Разбейте большие программные системы на гибкий состав взаимодействующих модулей.
- Поймите, где сосредоточить внимание на архитектуре
- Переносите крупномасштабные монолитные приложения в приложения с модульной архитектурой.
Два аспекта модульности
Есть два аспекта модульности.
Модель времени выполнения фокусируется на том, как управлять программными системами во время выполнения. Модульная система, такая как OSGi, необходима для использования модели времени выполнения.
Модель разработки описывает, как разработчики создают модульное программное обеспечение. Модель развития можно разбить на две подкатегории. Модель программирования – это то, как вы взаимодействуете с модульной структурой, чтобы воспользоваться преимуществами модульности во время выполнения.Парадигма дизайна – это набор шаблонов, которые вы применяете для разработки отличных модулей.
Модульная структура обеспечивает поддержку во время выполнения и модель программирования для модульности. Но модульная структура не поможет вам разрабатывать отличные программные модули. Шаблоны в этой справочной карточке обращаются к парадигме проектирования и помогают разрабатывать модульное программное обеспечение.
Определен модуль
Программный модуль – это развертываемая, управляемая, компоновочная единица программного обеспечения без сохранения состояния, которую можно использовать повторно, которая обеспечивает понятный интерфейс для потребителей.На платформе Java модуль представляет собой файл JAR, как показано на схеме. Шаблоны в этой справочной карточке помогут вам разрабатывать модульное программное обеспечение и реализовать преимущества модульности.
Что вообще означает модульная архитектура в Angular?
Идея модульности часто встречается, особенно в области чистого и структурированного кода. Это одна из тех идей, которая должна реализоваться сама собой, если вы достаточно часто повторяете ее в предложении.
Когда дело доходит до Angular, модульность – это больше, чем просто контейнеризация кода.Когда мы начинаем кодировать или изучать, как использовать Angular, мы часто прыгаем в первую очередь – в стиле YouTube-учебника и сразу в глубину. Если это работает, это работает, и мы часто просто останавливаемся на этом.
Однако модульность – это воплощение мыслительного процесса. Эти мысли и процессы проникают в код, который он должен представлять.
Итак, что вы думаете об Angular в модульном стиле?
Проблема, с которой сталкиваются многие разработчики, заключается в том, что владельцы и менеджеры бизнеса не понимают, что такое код на самом деле.Для них код – это нематериальное понятие, которое существует с таинственной аурой. Это также цель для средства, причем цели часто начинаются без определения того, каковы средства.
Проблемная область – это определение того, что вам нужно для решения конкретной проблемы. Это объем вашей работы, четкая граница того, что важно, а что нет. Это то, что дает нам точку A и точку B – созданное программное обеспечение является связующей линией между этими двумя точками.
Когда у нас нет четкой предметной области, у нас нет четкого представления о том, куда мы хотим двигаться с нашим кодом или как что-то создавать.Это все равно, что построить дом без архитектурных планов и просто дать строителям немного древесины и инструментов для работы. Вы можете получить дом, но структурная целостность здания не будет на том же уровне, что и дом, построенный по плану и по спецификации.
Когда мы начинаем с проблемной области, мы можем идентифицировать каждый компонент в системе и при необходимости абстрагироваться от них.
Но как определить проблемную область? Давайте посмотрим на гипотетический пример ниже.
Вашему другу Энди нужен абонемент в спортзал. Он знает, что хочет, чтобы участники имели возможность зарегистрироваться онлайн, ввести свои данные, а затем зарегистрироваться на вводном этапе. Он также хочет, чтобы инструкторы тренажерного зала могли получить доступ к сведениям об участниках и составить планы питания и тренировок для их программы тренировок.
Участники могут получить доступ только к своей собственной информации и ни к какой другой. Также есть администратор, который может добавлять в штат инструкторов тренажерного зала.
На первый взгляд это звучит как довольно простая и базовая система, однако она может стать излишне сложной, если не будет структурирована с четкими доменами.В приведенном выше брифинге мы можем выделить две вещи: роли и действия.
Есть три роли: администратор, участники и инструкторы тренажерного зала. Также есть четыре основных действия – возможность зарегистрироваться, заказать вводный курс, получить доступ к деталям и настроить планы.
Давайте посмотрим на них в наглядном виде.
Теперь, когда у нас есть все необходимые компоненты, пора наладить отношения между ними.
Проблемная область – это, по сути, причина, по которой мы создаем наше программное обеспечение.В данном случае нужно создать систему, которая сможет обрабатывать и воплощать идеи Энди. Что мы здесь сделали, так это изменили формат описания Энди проблемной области на систематический подход к визуализации того, как выглядят соединительные элементы между точками A и B.
Многие часто пропускают эту часть и сразу переходят к кодированию. Это приводит нас к тому, что мы просто создаем наш код без особого планирования или подтверждения перевода с Энди.
Хотя теоретически мы могли бы просто создать этот образ в наших головах, для более крупных и гораздо более сложных систем, где несколько человек работают в команде, этот процесс определения проблемной области проясняет, что необходимо, и составные части. требуется для создания наших модулей.
В простейшем случае модуль – это определенный фрагмент кода, который находится в вашей системе. Насколько хорошо это определено, зависит от того, насколько хорошо вам удалось перевести свои проблемные области.
Теоретически весь код можно разместить внутри одного модуля, но это не самый эффективный способ сделать это.
Модульное программирование – это метод разделения функций на независимые и взаимозаменяемые части. Код – это не пластилин и не головоломка.Скорее, это больше похоже на блоки Lego, если модули реализованы правильно.
Особенность Legos в том, что, хотя части могут легко вставляться друг в друга, они также могут быть разных размеров и типов. Некоторые части могут быть соединены только один раз, в то время как другие могут иметь особую форму, например, наклон.
Хотя детали стандартизированы, вариации – это то, что дает нам возможность создавать множество комбинаций. Насколько хорошо он сидит конструктивно, зависит от типа используемых деталей и их соединения друг с другом.
То же самое и с модулями.
В Angular есть два официальных типа модулей – корневые модули и функциональные модули. Однако мы можем далее разбить функциональные модули на их специализированные части, такие как модули маршрутизации, импортированные, компонентные, сервисы и виджеты.
В разрезе до самых основных частей все модули Angular выглядят одинаково. Единственное различие между ними – цель их существования. Объем этого существования определяет, насколько большим или маленьким окажется ваш модуль.
импортировать {SomeModule} из './someModule';
@NgModule ({})
класс экспорта AnExampleExportedModule {} Каждый модуль Angular имеет импорт, декоратор @NgModule и экспортируемый класс. Декоратор @NgModule сообщает Angular, что экспортируемый класс является модулем Angular. Ожидается, что в какой-то момент импортированные модули будут использоваться внутри класса, и этот класс эквивалентен блоку Lego.
Если бы вы использовали интерфейс командной строки для создания приложения Angular, генератор создал бы простое приложение с корнем и приложением .component.ts , в котором находится ваш основной модуль приложения.
Корень – или app.module.ts – это файл, который запускает процесс запуска вашего приложения Angular. Все начинается в этом файле, и без него ваше приложение Angular не сможет работать.
В корневом модуле он будет содержать все импортированные файлы, которые ссылаются на все, что вы в конечном итоге будете использовать. Думайте об этом как о библиотеке для предоставления будущих ресурсов. Это дает вашему приложению возможность обращаться к ним для использования, когда они необходимы.
Затем у нас есть функциональный модуль, также известный как остальная часть вашего приложения Angular. Однако функциональные модули не являются односторонними и разбиваются на разные категории в зависимости от функциональности.
Иметь модульный код – значит сгруппировать определенную идею. Построение модульной архитектуры означает создание кода, удовлетворяющего предметную область таким образом, чтобы код содержал стандартизованный способ соединения друг с другом, оставаясь в то же время независимым.
Существует несколько способов группировки идей, и в случае Angular предлагаемый объем модулей основан на наборах определенных характеристик и функций. Вот краткое описание различных типов, когда их использовать и почему.
Маршрутизация
Идея модуля маршрутизации состоит в том, чтобы централизовать все ваши маршруты в одном месте, а не распределять их по нескольким файлам. Когда дело доходит до маршрутизации, у вас обычно есть только один файл или несколько, которые разделены на типы ссылок, основанные на ролях.
Этот метод разделения на основе ролей не является окончательным, но это хороший способ сгруппировать информацию, а не хранить все в одном большом файле.
Модуль маршрутизации по существу покрывает перемещение по просмотрам и получение данных из адресной строки. Он не занимается декларациями и не несет никакой ответственности за пределами этой области.
Маршрутизированный
Официально он называется маршрутизируемым модулем. Однако многие из нас знают его как модуль, с которым связаны файлы html и css .
Если вы использовали интерфейс командной строки для генерации компонентов, команда будет выглядеть примерно так:
ng generate component
Этот тип модуля – это тот тип, в который мы часто помещаем все, потому что из-за формальность, вам разрешено. Но с точки зрения передовой практики это не лучший вариант.
Маршрутизируемый модуль является целью для маршрута. Его цель – действовать как модуль агрегатора, который объединяет все ваши другие модули в одном пространстве.Они не используются повторно никакими другими модулями и больше похожи на клей, который соединяет все части за кулисами, чтобы представление презентации отображалось по мере необходимости.
Это означает, что материал внутри маршрутизируемого компонентного модуля никогда не потребляется другим модулем – потому что на этом область действия и цель маршрутизируемого модуля заканчиваются.
В случае с нашим вымышленным бизнесом Gym Monkeys, маршрутизируемые модули реализуют отношения между различными ролями и действиями.
Домен
Модуль домена имеет дело с конкретным пользовательским интерфейсом, который повторяется в разных маршрутизируемых модулях.Например, определенная форма – например, форма регистрации – появляется в вашем приложении более одного раза.
Когда это произойдет, вы можете абстрагироваться от опыта, чтобы стандартизировать код. Это дает вам возможность импортировать его в маршрутизируемые модули. У них обычно нет провайдера – то есть того, кто занимается данными – и обычно они изначально считаются тупыми .
Если к ним подключены поставщики, жизненный цикл этого поставщика имеет ту же продолжительность, что и модуль домена.Это означает, что если модуль домена завершается из-за изменения маршрутизации, это еще не конец света.
Сервис
Сервисный модуль работает с данными. По сути, они представляют собой набор поставщиков, не имеющих ничего общего с представлениями. Они основаны на служебных программах и часто связаны с подключением приложения к внешним источникам данных.
Например, если вы хотите отправить форму регистрации во внешний API, вы не должны делать это в маршрутизируемых модулях или модулях домена. Скорее, вы извлечете его и поместите в сервисный модуль для будущего и неограниченного потребления.
Модули виджетов – это сторонние компоненты, директивы и каналы. Они похожи по концепции на модуль домена, за исключением того, что они не являются собственными для приложения.
Скорее, они часто импортируются в проект как дополнительные библиотеки. Например, библиотеки компонентов пользовательского интерфейса часто строятся как модули виджетов, потому что они распространяются независимо и не полагаются на работу служб.
В конце концов, модульный код – это, по сути, ваша способность систематизировать информацию по категориям, которые имеют смысл для размера вашего приложения.Не существует беспроигрышной универсальной сделки. и один метод мышления может быть слишком запутанным для небольших приложений или слишком ограниченным для более крупных приложений. Когда это происходит, рефакторинг неизбежен.
Модульная архитектура в Angular – это установка определенного разделения кода друг от друга в зависимости от области действия и проблемных областей.
Поначалу установка такой идеологии в код может показаться пугающей, но с практикой ее легче идентифицировать и реализовать.